6 minutes
Commandes Python de base pour Scikit-Learn
1. L’objet estimator
Dans Scikit les algorithmes de Machine Learning sont exposés via des objets appelés “estimator”.
Exemple pour une régression linéaire:
from sklearn.linear_model import LinearRegression
# Tous les paramètres pour configurer l'estimator peuvent être passé à l'objet lors de son instanciation
model = LinearRegression(normalize=True)
print(model)
Résultat:
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=True)
L’interface des méthodes de scikit-learn sont uniformes.
Pour tous les estimators:
- model.fit() : remplit le modèle avec des données d’entrainement. Pour un apprentissage supervisé, la méthode accepte 2 arguments: les données X et les labels y (i.e. model.fit(X, y)). Pour une apprentissage non supervisé, la méthode ne prend qu’un seul arguement, les données X (i.e. model.fit(X)).
Pour les estimators en apprentissage supervisé:
- model.predict() : prédire le label d’un ensemble de features à partir d’un modèle entrainé. La méthode accepte un argument, les nouvelles données X_new (i.e. model.predict(X_new) et retourne les labels prédits pour chaque objet du tableau.
- model.predict_proba() : Pour les problèmes de classification, certains estimators fournissent cette méthode qui retourne la probabilité qu’une nouvelle observation possède chaque label. La label qui la plus forte probabilité est retourné par model.predict().
- model.score() : Pour les problèmes de régession ou de classification, les estimators implémentent une méthode de score. Cette dernière permet d’indiquer si le fit est bon ou pas. Le score peut varier entre 0 et 1.
2. Ajouter des données à l'estimator
%matplotlib inline
import numpy as np
from matplotlib import pyplot as plt
x = np.array([0, 1, 2])
y = np.array([0, 1, 2])
_ = plt.plot(x, y, marker='o')
Résultat:
X = x[:, np.newaxis] # On incrémente la dimension car scikit prend un tableau à 2 dimensions en input: (samples == 3 x features == 1)
model.fit(X, y)
model.coef_ # Paramètre estimé par scikit à partir des données ajoutées. Tous les paramètres estimés par scikit se terminent un _.
3. Apprentissage supervisé: Classification et Régression
En apprentissage supervisé, on a un dataset qui contient à la fois des features et des labels. L’objectif est de construire un estimator qui est capable de prédire le label d’un objet à partir d’un ensemble de features. En classification, le label est valeur discrète alors qu’en régression le label est une valeur continue.
3.1. Classification
KNN (K Nearest Neighbors) ou “K voisins les plus proches” en français est un des algorithmes les plus simples à appréhender: Pour une toute nouvelle observation, regarder dans une base de référence, quelle observation a ses features les plus proches et lui assigner la classe prédominante.

# On charge d'abord le dataset Iris
from sklearn import neighbors, datasets
iris = datasets.load_iris()
# On extrait les features et labels du dataset
X, y = iris.data, iris.target
# On instancie l'*estimator*
knn = neighbors.KNeighborsClassifier(n_neighbors=1)
# n_neighbors=1 signifie que le nombre de voisin(s) à avoir égal à 1
# On remplit l'*estimator* avec les données
knn.fit(X, y)
# On prédit l'Iris qui a les caractéristiques (features) suivantes:
# sépale = 4cm x 3cm et pétale = 5cm x 2cm
print(iris.target_names[knn.predict([[4, 3, 5, 2]])])
Résultat:
['virginica']
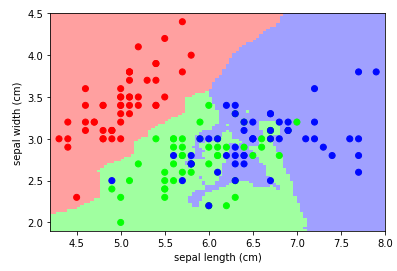
Afficher un scatter plot des features longeur et largeur des sépales ainsi que la préduction du KNN
Exemple complet:
# On charge le dataset
from sklearn import neighbors, datasets
iris = datasets.load_iris()
# On mappe 3 couleurs ou les 3 classes du problème
from matplotlib.colors import ListedColormap
cmap_light = ListedColormap(['#FFAAAA', '#AAFFAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#00FF00', '#0000FF'])
X = iris.data[:, :2] # On prend les 2 features liées aux sépales
y = iris.target
knn = neighbors.KNeighborsClassifier(n_neighbors=3)
knn.fit(X, y)
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() + .1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
Z = knn.predict(np.c_[xx.ravel(), yy.ravel()])
# On plot le résultat
Z = Z.reshape(xx.shape)
plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# On plot également les points d'entrainement
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold)
plt.xlabel('sepal length (cm)')
plt.ylabel('sepal width (cm)')
plt.axis('tight')
Résultat:
3.2. Régression
La régression la plus simple est la régression linéaire. Voici un exemple:
On crée des données aléatoires:
import numpy as np
np.random.seed(0)
X = np.random.random(size=(20, 1))
y = 3 * X[:, 0] + 2 + np.random.normal(size=20)
print(X)
print(X.shape)
print(y)
print(y.shape)
Résultat:
[[0.5488135 ]
[0.71518937]
[0.60276338]
[0.54488318]
[0.4236548 ]
[0.64589411]
[0.43758721]
[0.891773 ]
[0.96366276]
[0.38344152]
[0.79172504]
[0.52889492]
[0.56804456]
[0.92559664]
[0.07103606]
[0.0871293 ]
[0.0202184 ]
[0.83261985]
[0.77815675]
[0.87001215]]
(20, 1)
[5.14051958 3.94040984 4.12135783 2.78055381 0.71797458 4.59130093
4.17719783 3.93315398 7.16074291 1.69595888 4.42093363 3.39950091
5.2369129 6.24614868 2.3680556 2.63955042 1.17286944 2.51706307
3.9865581 4.76638541]
(20,)
On remplit l'estimator avec ces données:
from sklearn.linear_model import LinearRegression
model = LinearRegression(fit_intercept=True)
model.fit(X, y)
print("Model coefficient: %.5f, and intercept: %.5f"
% (model.coef_, model.intercept_))
Résultat:
Model coefficient: 3.93491, and intercept: 1.46229
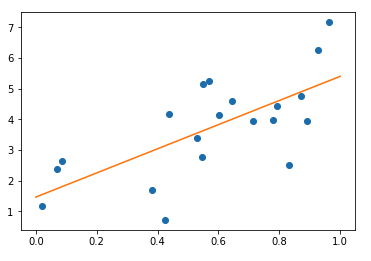
On affiche le graphique et le modèle prédictif
# On affiche les données d'entrainement
import pylab as pl
plt.plot(X[:, 0], y, 'o')
# On prédit les labels pour 100 points allant de 0 à 1 qu'on ajoute au graphique précédent
X_test = np.linspace(0, 1, 100)[:, np.newaxis]
y_test = model.predict(X_test)
plt.plot(X_test[:, 0], y_test)
Résultat:
4. Régularisation
Cela permet de, comme son nom d’indique, régulariser les erreurs d’apprentissage. Supposez que vous créez un estimator KNN avec k=1, il est évident qu’il y aura des erreurs sur vos données d’apprentissage.
Wikipédia “La régularisation fait référence à un processus consistant à ajouter de l’information à un problème pour éviter le surapprentissage”
L’idée principale de la régularisation est qu’il est préférable de construire des modèles plus simples même s’ils conduisent à plus d’erreurs sur les données d’apprentissage.
Un schéma vaut mieux qu’un long discours
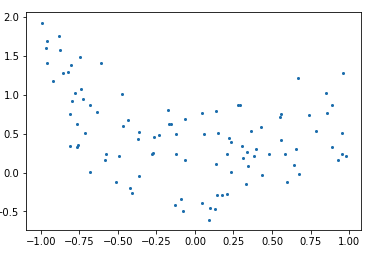
On part des données suivantes:
import numpy as np
rng = np.random.RandomState(0)
x = 2 * rng.rand(100) - 1
f = lambda t: 1.2 * t ** 2 + .1 * t ** 3 - .4 * t ** 5 - .5 * t ** 9
y = f(x) + .4 * rng.normal(size=100)
plt.figure()
plt.scatter(x, y, s=4)
Résultat:
On remplit 2 estimateurs avec des données ayant des polynômes 4 et 9.
x_test = np.linspace(-1, 1, 100)
plt.figure()
plt.scatter(x, y, s=4)
X = np.array([x**i for i in range(5)]).T
X_test = np.array([x_test**i for i in range(5)]).T
order4 = LinearRegression()
order4.fit(X, y)
plt.plot(x_test, order4.predict(X_test), label='4th order')
X = np.array([x**i for i in range(10)]).T
X_test = np.array([x_test**i for i in range(10)]).T
order9 = LinearRegression()
order9.fit(X, y)
plt.plot(x_test, order9.predict(X_test), label='9th order')
plt.legend(loc='best')
plt.axis('tight')
plt.title('Fitting a 4th and a 9th order polynomial')
Résultat:
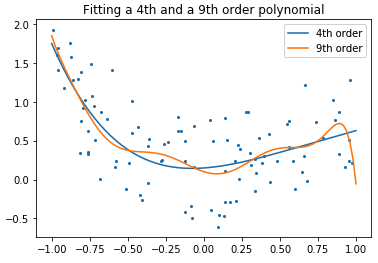
Quelle courbe préférez-vous ?
Le polynôme de degré 9 a tendance à passer par tous les points du graphique. Il va intégrer le bruit spécifique à l’échantillon d’entraînement; ce qui conduira notre modèle à ne pas avoir une bonne performance sur de nouveaux exemples.
Un des risques majeurs avec ce type de modèles est le surapprentissage. La régularisation donc, est une technique permettant de (régulariser) rêgler ce phénomène.