2 minutes
Comment lire une Matrice de confusion
Chaque colonne de la matrice représente le nombre d’occurrences d’une classe estimée, tandis que chaque ligne représente le nombre d’occurrences d’une classe réelle (ou de référence). Les occurrences utilisées pour chacune de ces 2 classes doivent être différentes.
Exemple:
On considère un système de classification dont le but est de classer du mail (courrier électronique) en deux classes:
- courriel pertinent ou
- pourriel intempestif.
On va vouloir savoir:
- Combien de courriels seront faussement estimés comme des pourriels (fausses alarmes) et
- combien de pourriels ne seront pas estimés comme tels (non détections) et donc classifiés comme courriels.
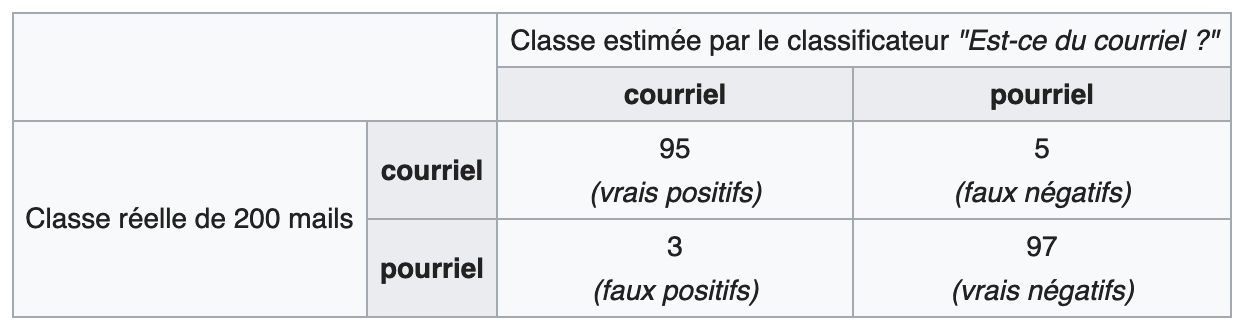
On va supposer qu’on a expérimenté notre classificateur sur 100 courriels et sur 100 pourriels, constituant ainsi un jeu initial de 200 mails correspondant au contenu de la classe réelle.
La matrice de confusion suivante se lit alors comme suit:
- horizontalement, sur les 100 courriels initiaux (ie : 95+5), 95 ont été estimés par le système de classification comme tels et 5 ont été estimés comme pourriels (ie : 5 faux-négatifs),
- horizontalement, sur les 100 pourriels initiaux (ie : 3+97), 3 ont été estimés comme courriels (ie : 3 faux-positifs) et 97 ont été estimés comme pourriels,
- verticalement, sur les 98 mails (ie : 95+3) estimés par le système comme courriels, 3 sont en fait des pourriels,
- verticalement, sur les 102 mails (ie : 5+97) estimés par le système comme pourriels, 5 sont en fait des courriels.
Source: Wikipedia.fr