3 minutes
Régression linéaire avec Tensorflow 2
Introduction
Pourquoi multiplier les framework Machine Learning quand on peut tout faire avec Tensorflow ? C’est une de mes reflexions du moment. Dans cet article, nous allons voir à quel point il est simple de faire une regression linéaire avec Tensorflow 2 avec le dataset Boston Housing.
Régression linéaire
Chargement des modules:
from __future__ import print_function, absolute_import, unicode_literals, division
import tensorflow as tf
import seaborn as sb
import numpy as np
import pandas as pd
from tensorflow.estimator import LinearRegressor
from tensorflow import keras as ks
from sklearn import datasets
from sklearn.metrics import mean_squared_error, r2_score
from sklearn.model_selection import train_test_split
Chargement du dataset:
boston_load = datasets.load_boston()
feature_columns = boston_load.feature_names
target_column = boston_load.target
boston_data = pd.DataFrame(boston_load.data, columns=feature_columns).astype(np.float32)
boston_data['MEDV'] = target_column.astype(np.float32)
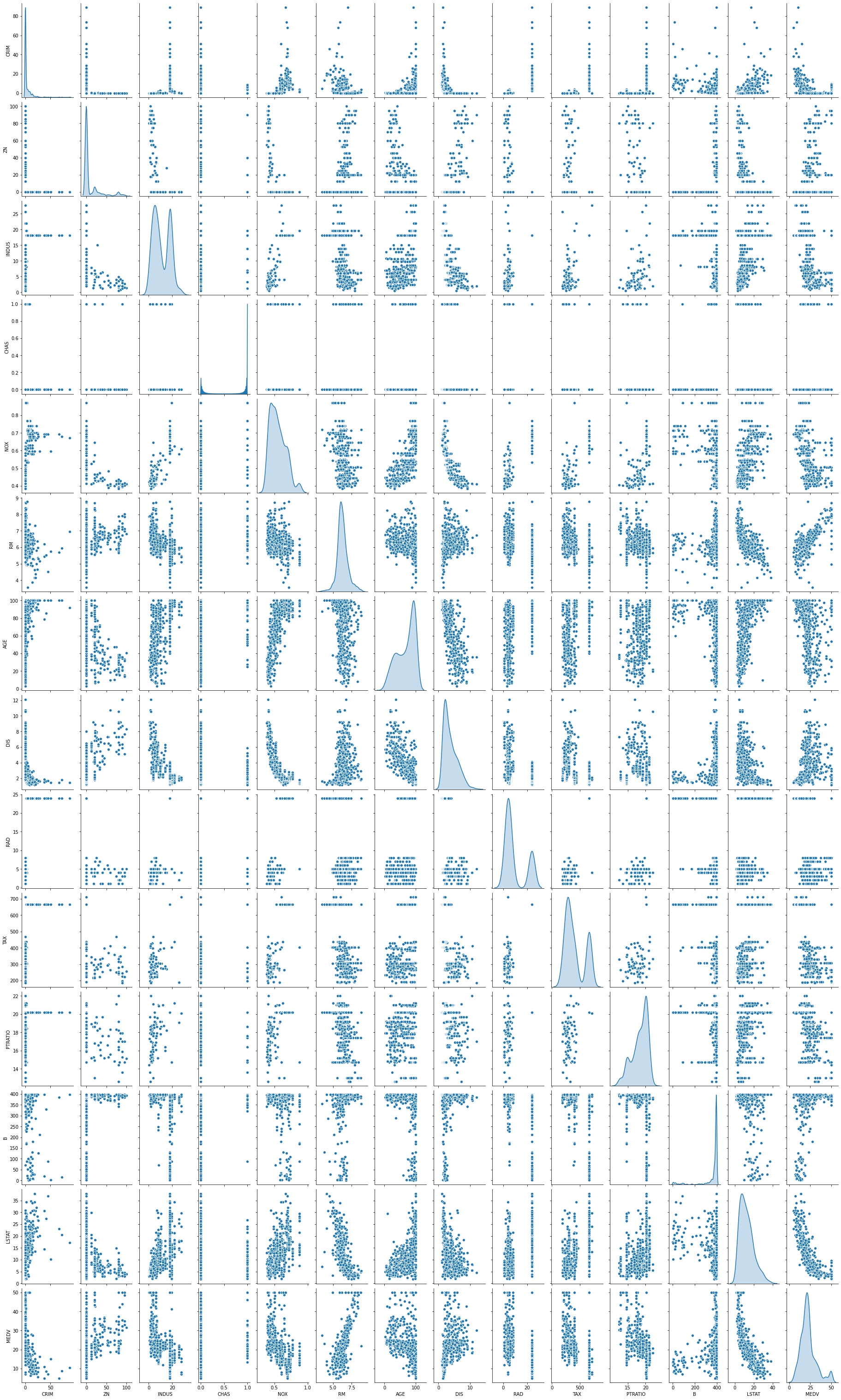
Analyse des corrélations entre les données:
sb.pairplot(boston_data, diag_kind="kde", height=3, aspect=0.6)
correlation_data = boston_data.corr()
correlation_data.style.background_gradient(cmap='coolwarm', axis=None)

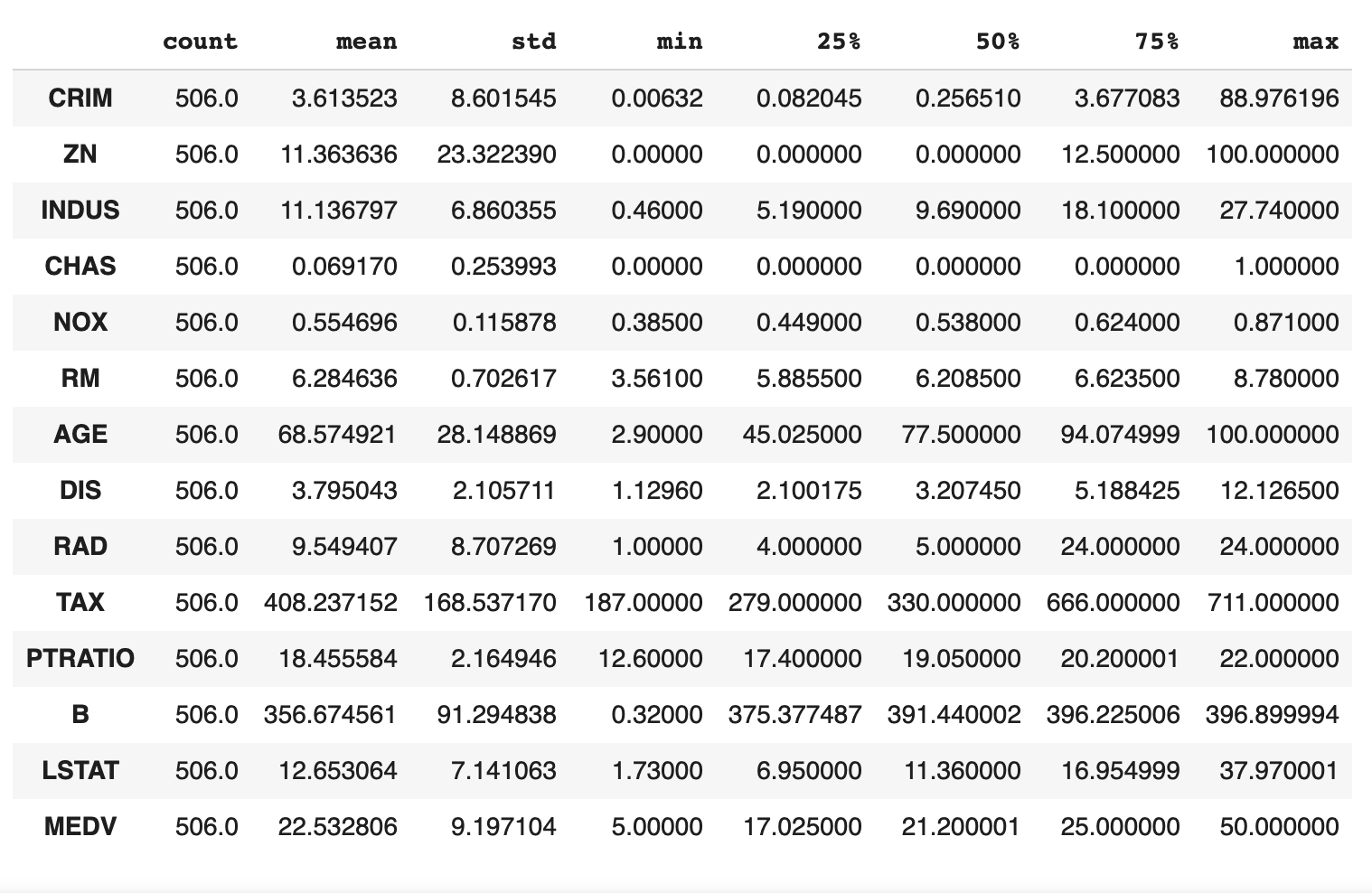
Statistiques sur les données:
stats = boston_data.describe()
boston_stats = stats.transpose()
print(boston_stats)
Sélection des donneées:
X_data = boston_data[[i for i in boston_data.columns if i not in ['MEDV']]]
Y_data = boston_data[['MEDV']]
Split Train Test:
training_features , test_features ,training_labels, test_labels = train_test_split(X_data , Y_data , test_size=0.2)
print('Number of rows in Training Features: ', training_features.shape[0])
print('Number of rows in Test Features: ', test_features.shape[0])
print('Number of columns in Training Features: ', training_features.shape[1])
print('Number of columns in Test Features: ', test_features.shape[1])
print('Number of rows in Training Label: ', training_labels.shape[0])
print('Number of rows in Test Label: ', test_labels.shape[0])
print('Number of columns in Training Label: ', training_labels.shape[1])
print('Number of columns in Test Label: ', test_labels.shape[1])
stats = training_features.describe()
stats = stats.transpose()
print(stats)
stats = test_features.describe()
stats = stats.transpose()
print(stats)
Normalisation des données:
def normalize(x):
stats = x.describe()
stats = stats.transpose()
return (x - stats['mean']) / stats['std']
normed_train_features = normalize(training_features)
normed_test_features = normalize(test_features)
Construction de la pipeline d’input pour construire le modèle TensorFlow:
def feed_input(features_dataframe, target_dataframe, num_of_epochs=10, shuffle=True, batch_size=32):
def input_feed_function():
dataset = tf.data.Dataset.from_tensor_slices((dict(features_dataframe), target_dataframe))
if shuffle:
dataset = dataset.shuffle(2000)
dataset = dataset.batch(batch_size).repeat(num_of_epochs)
return dataset
return input_feed_function
train_feed_input = feed_input(normed_train_features, training_labels)
train_feed_input_testing = feed_input(normed_train_features, training_labels, num_of_epochs=1, shuffle=False)
test_feed_input = feed_input(normed_test_features, test_labels, num_of_epochs=1, shuffle=False)
Entrainement du modèle:
feature_columns_numeric = [tf.feature_column.numeric_column(m) for m in training_features.columns]
linear_model = LinearRegressor(feature_columns=feature_columns_numeric, optimizer='RMSProp')
linear_model.train(train_feed_input)
Prédictions:
train_predictions = linear_model.predict(train_feed_input_testing)
test_predictions = linear_model.predict(test_feed_input)
train_predictions_series = pd.Series([p['predictions'][0] for p in train_predictions])
test_predictions_series = pd.Series([p['predictions'][0] for p in test_predictions])
train_predictions_df = pd.DataFrame(train_predictions_series, columns=['predictions'])
test_predictions_df = pd.DataFrame(test_predictions_series, columns=['predictions'])
training_labels.reset_index(drop=True, inplace=True)
train_predictions_df.reset_index(drop=True, inplace=True)
test_labels.reset_index(drop=True, inplace=True)
test_predictions_df.reset_index(drop=True, inplace=True)
train_labels_with_predictions_df = pd.concat([training_labels, train_predictions_df], axis=1)
test_labels_with_predictions_df = pd.concat([test_labels, test_predictions_df], axis=1)
Validation:
def calculate_errors_and_r2(y_true, y_pred):
mean_squared_err = (mean_squared_error(y_true, y_pred))
root_mean_squared_err = np.sqrt(mean_squared_err)
r2 = round(r2_score(y_true, y_pred)*100,0)
return mean_squared_err, root_mean_squared_err, r2
train_mean_squared_error, train_root_mean_squared_error, train_r2_score_percentage = calculate_errors_and_r2(training_labels, train_predictions_series)
test_mean_squared_error, test_root_mean_squared_error, test_r2_score_percentage = calculate_errors_and_r2(test_labels, test_predictions_series)
print('Training Data Mean Squared Error = ', train_mean_squared_error)
print('Training Data Root Mean Squared Error = ', train_root_mean_squared_error)
print('Training Data R2 = ', train_r2_score_percentage)
print('Test Data Mean Squared Error = ', test_mean_squared_error)
print('Test Data Root Mean Squared Error = ', test_root_mean_squared_error)
print('Test Data R2 = ', test_r2_score_percentage)
Output:
Training Data Mean Squared Error = 23.667924020459342
Training Data Root Mean Squared Error = 4.864969066752567
Training Data R2 = 72.0
Test Data Mean Squared Error = 20.22803996987049
Test Data Root Mean Squared Error = 4.497559334780419
Test Data R2 = 77.0