8 minutes
Basics Python commands pour Matplotlib, Numpy, Pandas et debugging misc
Voici une liste des commandes de base pour commencer à travailler avec Matplotlib et Pandas et Numpy.
1. Charger un dataset
On charge un dataset basic (fleurs Iris très connu). On s’en sert ensuite dans l’affichage d’un nuage de points avec Matplotlib.
from sklearn.datasets import load_iris
iris = load_iris()
n_samples, n_features = iris.data.shape
print(n_samples)
print(n_features)
# 150
# 4
2. Afficher un nuage de points (scatter plot)
On considère travailler avec un array (150,4). Voir point 1.
# La commande qui suit permet de ne pas avoir de problème avec l'affichage de graphiques dans Jupyter Notebook
%matplotlib inline
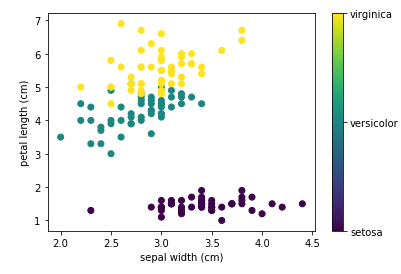
Affichage du scratter plot:
from matplotlib import pyplot as plt
x_index = 1
y_index = 3
# Ce formateur permet de remplacer les index des classes d'iris par leur nom dans la légende
formatter = plt.FuncFormatter(lambda i, *args: iris.target_names[int(i)])
plt.scatter(iris.data[:, x_index], iris.data[:, y_index], c=iris.target)
plt.colorbar(ticks=[0, 1, 2], format=formatter)
plt.xlabel(iris.feature_names[x_index])
plt.ylabel(iris.feature_names[y_index])
Résultat:
3. Manipuler des Numpy Arrays
3.1. Générer un tableau aléatoire
import numpy as np
X = np.random.random((3,5))
print(X)
Résultat:
[[0.74271281 0.89627097 0.95309957 0.48770972 0.3841344 ]
[0.32855405 0.11656708 0.63427992 0.51111629 0.53846283]
[0.99568791 0.44366564 0.0842925 0.12422041 0.38149375]]
3.2. Accéder à des éléments d’un numpy array
# Accéder à un seul élément
print(X[0,0])
# Accéder à une ligne
print(X[0,:]) ou print(X[0])
# Accéder à une colonne
print(X[:,0]
Résultat:
0.7427128108295802
[0.74271281 0.89627097 0.95309957 0.48770972 0.3841344 ]
[0.74271281 0.32855405 0.99568791]
3.3. Faire une transposée de Matrice (les lignes deviennent les colonnes)
print(X.T)
Résultat:
[[0.74271281 0.32855405 0.99568791]
[0.89627097 0.11656708 0.44366564]
[0.95309957 0.63427992 0.0842925 ]
[0.48770972 0.51111629 0.12422041]
[0.3841344 0.53846283 0.38149375]]
3.4. Faire un range sans être gêné par le dernier élement
Cette méthode permet d’obtenir un tableau à une dimension allant d’une valeur de départ à une valeur de fin avec un nombre donné d’éléments.
# la fonction linspace(premier, dernier, n) évite tout désagrément
np.linspace(1., 4., 6)
Résultat:
# array([ 1. , 1.6, 2.2, 2.8, 3.4, 4. ])
3.5. Incrémenter la dimension d’un array (Permet également de convertir explicitement un array à 1 dimension en un vecteur ligne ou vecteur colonne.)
A = np.array([2, 0, 1, 8])
print(A)
A.shape
# [2 0 1 8]
# (4,)
B = A[np.newaxis, :]
print(B)
B.shape
# [[2 0 1 8]]
# (1, 4)
C = A[:, np.newaxis]
print(C)
C.shape
# [[2]
[0]
[1]
[8]]
# (4,1)
Alternatives:
np.expand_dims(A, 1) # équivaut à A[:, np.newaxis]
np.expand_dims(A, 0) # équivaut à A[np.newaxis, :]
ou
A.reshape(A.shape + (1,)) # équivaut à A[:, np.newaxis]
A.reshape((1,) + A.shape) # équivaut à A[np.newaxis, :]
3.6. Convertir une liste Python en Numpy Array
ma_liste = [1,2,3]
x = np.array(ma_liste)
3.7. Créer un tableau de 20 zéros
np.zeros(20)
3.8. Créer un tableau de 20 uns
np.ones(20)
3.9. Créer un tableau de 20 neuf
np.ones(20) * 9
3.10. Créer un tableau d’entiers de 20 à 50
np.arange(20,51)
3.11. Créer un tableau d’entiers pairs entre 20 et 50
np.arange(20,51,2)
3.12. Créer une matrice 3x3 avec les valeurs de 0 à 8
np.arange(0,9).reshape(3,3)
3.13. Créer une matrice identité 3x3
np.eye(3)
3.14. Générer un nombre aléatoire entre 0 et 1
np.random.rand(1)
3.15. Générer un tableau de 25 nombres aléatoires échantillonnés à partir d’une distribution normale standard
np.random.randn(25)
3.16. Créer un tableau de 50 points espacés linéairement entre 0 et 1
np.linspace(0,1,20)
3.17. Calculer la somme de toutes les colonnes d’une matrice
ma_matrice.sum(axis=0)
3.18. Calculer l’écart-type des valeurs d’une matrice
ma_matrice.std()
4. Manipuler des Scipy Sparse Matrices
Ces matrices sont parfois utiles lorsque le dataset est extrèmement grand (millions de features) et qu’il n’y a presque que des 0 pour un échantillon donné.
On crée une matrice avec des données aléatoires
from scipy import sparse
X = np.random.random((10, 5))
print(X)
Résultat:
[[0.74668664 0.28468523 0.31235423 0.85889384 0.44178508]
[0.42935032 0.12811469 0.10010876 0.44757517 0.85568623]
[0.52500676 0.81764407 0.32380153 0.41696393 0.46913849]
[0.38276909 0.93648265 0.19733164 0.42392672 0.75220776]
[0.71149141 0.21479105 0.93260534 0.44922132 0.1069613 ]
[0.81701 0.85721634 0.43327147 0.07404298 0.00268589]
[0.41816508 0.45835663 0.13466681 0.65741327 0.19939561]
[0.87886815 0.90599216 0.60680106 0.52665484 0.69824682]
[0.75469648 0.89312007 0.10350947 0.48109062 0.61979146]
[0.90195641 0.48118575 0.95517067 0.86300827 0.36144463]]
On fixe la majorité des éléments à 0
X[X < 0.7] = 0
print(X)
Résultat:
[[0.74668664 0. 0. 0.85889384 0. ]
[0. 0. 0. 0. 0.85568623]
[0. 0.81764407 0. 0. 0. ]
[0. 0.93648265 0. 0. 0.75220776]
[0.71149141 0. 0.93260534 0. 0. ]
[0.81701 0.85721634 0. 0. 0. ]
[0. 0. 0. 0. 0. ]
[0.87886815 0.90599216 0. 0. 0. ]
[0.75469648 0.89312007 0. 0. 0. ]
[0.90195641 0. 0.95517067 0.86300827 0. ]]
On convertit X en une Matrice CSR (Compressed-Sparse-Row)
X_csr = sparse.csr_matrix(X)
print(X_csr)
Résultat:
(0, 0) 0.7466866354064811
(0, 3) 0.858893836600347
(1, 4) 0.8556862339513924
(2, 1) 0.8176440715795563
(3, 1) 0.9364826540107359
(3, 4) 0.7522077587621511
(4, 0) 0.7114914132345445
(4, 2) 0.9326053405778985
(5, 0) 0.8170100021133657
(5, 1) 0.8572163407003378
(7, 0) 0.8788681533625899
(7, 1) 0.9059921645080171
(8, 0) 0.7546964834006666
(8, 1) 0.893120069181746
(9, 0) 0.9019564067395904
(9, 2) 0.9551706684658897
(9, 3) 0.8630082740227074
On rétablit la Matrice Sparse en numpy array
print(X_csr.toarray())
Résultat:
[[0.74668664 0. 0. 0.85889384 0. ]
[0. 0. 0. 0. 0.85568623]
[0. 0.81764407 0. 0. 0. ]
[0. 0.93648265 0. 0. 0.75220776]
[0.71149141 0. 0.93260534 0. 0. ]
[0.81701 0.85721634 0. 0. 0. ]
[0. 0. 0. 0. 0. ]
[0.87886815 0.90599216 0. 0. 0. ]
[0.75469648 0.89312007 0. 0. 0. ]
[0.90195641 0. 0.95517067 0.86300827 0. ]]
5. Visualisation des données avec Matplotlib
5.1. Afficher une fonction simple
import matplotlib.pyplot as plt
# Afficher une ligne
x = np.linspace(0, 10, 100)
plt.plot(x, np.sin(x))
Résultat:
5.2. Afficher un nuage de points (scatter plot)
import matplotlib.pyplot as plt
x = np.random.normal(size=500)
y = np.random.normal(size=500)
plt.scatter(x, y)
Résultat:
5.3. Tracer une image
import matplotlib.pyplot as plt
x = np.linspace(1, 12, 100)
y = x[:, np.newaxis]
im = y * np.sin(x) * np.cos(y)
plt.imshow(im)
Résultat:
5.4. Tracer les contours
import matplotlib.pyplot as plt
x = np.linspace(1, 12, 100)
y = x[:, np.newaxis]
im = y * np.sin(x) * np.cos(y)
plt.contour(im)
Résultat:
5.5. Gallerie d’exemples
Des centaines d’exemples sont disponibles sur le site de Matplotlib. En exécutant la commande suivante dans votre notebook, le code source sera téléchargé. Vous n’aurez plus qu’à le ré-excuter pour qu’un graphique s’affiche.
%load http://matplotlib.org/mpl_examples/pylab_examples/ellipse_collection.py
5.6. Graphique 3D
# 3D
from mpl_toolkits.mplot3d import Axes3D
ax = plt.axes(projection='3d')
xgrid, ygrid = np.meshgrid(x, y.ravel())
ax.plot_surface(xgrid, ygrid, im, cmap=plt.cm.jet, cstride=2, rstride=2, linewidth=0)
Résultat:
5.7. Afficher matplotlib dans Jupyter Notebook et tracer un chart façon objet
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
x = np.arange(0,100)
y = x*2
z = x**2
fig = plt.figure()
ax = fig.add_axes([0,0,1,1])
ax.plot(x,y)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_title('title')
Résultat:
5.8. Afficher une petit chart à l’intérieur d’un (grand) chart
import matplotlib.pyplot as plt
%matplotlib inline
import numpy as np
x = np.arange(0,100)
y = x*2
z = x**2
fig = plt.figure()
ax1 = fig.add_axes([0,0,1,1])
ax1.plot(x,y,color='r')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax2 = fig.add_axes([.2,.5,.2,.2])
ax2.plot(x,y,color='r')
ax2.set_xlabel('x')
ax2.set_ylabel('y')
Résultat:
5.9. Zoomer sur une partir du chart
ax2.set_xlim([20,22])
ax2.set_ylim([30,50])
5.10. Afficher 2 charts les uns à côté des autres
fig, axes = plt.subplots(nrows=1, ncols=2,figsize=(12,2))
axes[0].plot(x,y,color="purple", lw=3, ls='-')
axes[1].plot(x,z,color="red", lw=3, ls='--')
6. Pandas
6.1. Charger, convertir un CSV en dataframe et afficher ses 5ère lignes
import pandas as pd
df = pd.read_csv('mon_dataset.csv')
df.head()
6.2. Afficher le nom des colonnes du dataframe
df.columns
6.3. Afficher le nombre d’éléments uniques d’une colonne d’un dataframe
len(df['colonne_name'].unique())
# Or
df['colonne_name'].nunique()
6.4. Afficher les éléments uniques d’une colonne d’un dataframe
df['colonne_name'].unique()
6.5. Afficher les 5 groupes de données ayant le plus d’éléments dans la colonne X
df.groupby("GroupByGroupe").count().sort_values('X', ascending=False).iloc[:5]['X']
6.6. Afficher le nombre de fois que des valeurs sont retournées dans les éléments d’une colonne
df['ma_colonne'].value_counts()
# Pour afficher le top 5
df['ma_colonne'].value_counts().iloc[:5]
6.7. Combien de ligne d’un dataframe n’ont pas la string “blabla” dans les valeurs de la colonne ma_colonne
sum(df['ma_colonne'].apply(lambda nom: 'blabla' not in nom))
6.8. Afficher le nombre de lignes que possède un dataframe ayant la valeur “toto” dans la colonne ma_colonne
df[df["ma_colonne"] == "toto"]
6.9. Pour une série temporelle, combien d’éléments y a-t-il dans notre dataframe avec une date supérieure à l’annéee 2020
sum(pd.to_datetime(df['date']).apply(lambda date: date.year) == 2020)
6.10. Exploser le dict d’une colonne d’un dataframe
Pour exploser un dictionnaire présent dans une colonne de son dataframe et ajouter les éléments du dictionnaire en tant que nouvelles colonnes dans le même DataFrame d’origine, on peut utiliser le code suivant:
df = pd.concat([df, df['ma_colonne'].apply(pd.Series)], axis=1)
df.drop('ma_colonne', axis=1, inplace=True)
6.11. Exploser un JSON imbriqué avec un structure hiérarchique
# Utilisez json_normalize pour exploser le dictionnaire dans un nouveau dataframe
new_df = pd.json_normalize(df['ma_colonne'])
# Ajoutez les colonnes résultantes à votre DataFrame d'origine
df = pd.concat([df, new_df], axis=1)
# Eventuellement supprimez la colonne d'origine contenant le dictionnaire
df.drop('ma_colonne', axis=1, inplace=True)
6.12. Renommer des colonnes
df.rename(
columns={
"ma_ma_colonne1": "ma_colonne1",
"ma_ma_colonne2": "ma_colonne2",
},
inplace=True,
)
6.13. Retourner la première ligne d’un dataframe dont la valeur est supérieur à 0
import pandas as pd
condition = df['ma_colonne'] > 0
# la méthode "loc" permet d'obtenir les lignes qui remplissent la condition
# puis iloc permet de retourner la première
first_row = df.loc[condition].iloc[0]
Debugging Misc
“Dumper” un objet
def dump(obj):
for attr in dir(obj):
if hasattr( obj, attr ):
print( "obj.%s = %s" % (attr, getattr(obj, attr)))
Afficher des couleurs dans le terminal
print('\x1b[6;30;42m' + 'Success!' + '\x1b[0m')

Voir toutes les couleurs disponibles:
def print_format_table():
"""
prints table of formatted text format options
"""
for style in range(8):
for fg in range(30,38):
s1 = ''
for bg in range(40,48):
format = ';'.join([str(style), str(fg), str(bg)])
s1 += '\x1b[%sm %s \x1b[0m' % (format, format)
print(s1)
print('\n')
print_format_table()
Voici quelques examples:
