14 minutes
Mastering Pandas
Cela fait pas mal de temps que j’utilise Pandas. Dans cet article je vais essayer de réunir et synthétiser tous les tips & tricks à savoir (comme si j’utilisais Jupyter Notebook).
Voici la liste des tips:
- Introduction à Pandas
- Lire des données tabulaires
- Sélectionner une série Pandas
- Parenthèses Pandas
- Renommer des colonnes
- Effacer une colonne
- Effacer toutes les colonnes sauf
- Trier
- Filtrer
- Filtres multi-critères
- Examiner un dataset
- Numéro, index et contenu de la ligne lors d’une itération
Introduction à Pandas
C’est une librairie opensource d’analyse de données qui fourni des structures de données ainsi que des outils d’analyse faciles à utiliser.
Ses avantages sont:
- Un grand nombre de fonctionnalités
- Une communauté active
- Documentation bien faite
- S’associe bien avec d’autres packages connus
- construit au-dessus de Numpy
- s’utilise facilement avec Scikit-learn
Lien vers la documentation officielle: http://pandas.pydata.org/
Lire des données tabulaires
Lire des fichiers de données tabulaires dans Pandas
Example de fichiers de données:
- CSV
- Excel
- Table-like data format
# import pandas
import pandas as pd
# reading a well-formatted .tsv file
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/chipotle.tsv'
orders = pd.read_table(url)
orders.head()
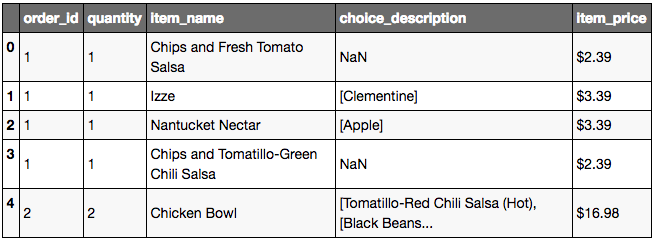
Fonctionnement par default de read_table:
- Le fichier à charger doit contenir des tabs entre les colonnes
- Présence d’un header
url2 = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/u.user'
users = pd.read_table(url2)
users.head()
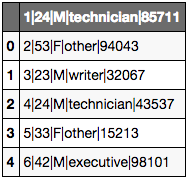
Problème:
- Le sepérateur entre les colonnes est le caractère
"|". Il faut donc le spécifier à Pandas avec le paramètresep= - Il n’y a pas de header. Il faut donc le spécifier en passant le paramètre
header=None. On peut aussi ajouter une ligne pour les noms des colonnes en utilisant le paramètrenames=user_cols
user_cols = ['user_id', 'age', 'gender', 'occupation', 'zip_code']
users = pd.read_table(url2, sep='|', header=None, names=user_cols)
users.head()
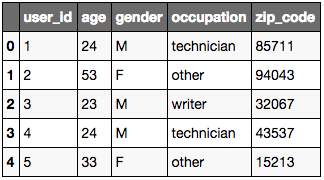
Note:
Si vous avez un fichier contenant du texte en haut ou en bas vous pouvez utiliser les paramètres suivants: skiprows=None ou skipfooter=None.
Lien vers la documentation de read_table: http://pandas.pydata.org/pandas-docs/stable/generated/pandas.read_table.html
Sélectionner une série Pandas
Sélectionner une série Pandas à partir d’un dataframe
Qu’est-ce qu’une série ?
- c’est un vecteur m x 1
- m est le nombre de lignes
- 1 le nombre de colonne
- Chaque colonne d’un dataframe Pandas est une série
import pandas as pd
# The csv file is separated by commas
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/ufo.csv'
# method 1: read_table
ufo = pd.read_table(url, sep=',')
# method 2: read_csv
# this is a short-cut here using read_csv because it uses comma as the default separator
ufo = pd.read_csv(url)
ufo.head()
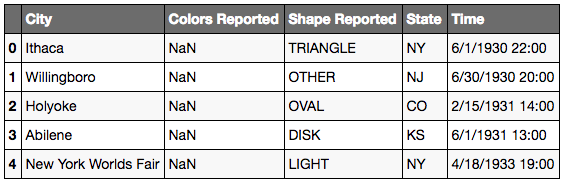
# Method 1: Selecting City series (this will always work)
ufo['City']
# Method 2: Selecting City series
ufo.City
# 'City' is case-sensitive, you cannot use 'city'
Jupyter Output:
0 Ithaca
1 Willingboro
2 Holyoke
3 Abilene
4 New York Worlds Fair
5 Valley City
6 Crater Lake
7 Alma
8 Eklutna
9 Hubbard
10 Fontana
11 Waterloo
12 Belton
13 Keokuk
14 Ludington
15 Forest Home
16 Los Angeles
17 Hapeville
18 Oneida
19 Bering Sea
20 Nebraska
21 NaN
22 NaN
23 Owensboro
24 Wilderness
25 San Diego
26 Wilderness
27 Clovis
28 Los Alamos
29 Ft. Duschene
...
18211 Holyoke
18212 Carson
18213 Pasadena
18214 Austin
18215 El Campo
18216 Garden Grove
18217 Berthoud Pass
18218 Sisterdale
18219 Garden Grove
18220 Shasta Lake
18221 Franklin
18222 Albrightsville
18223 Greenville
18224 Eufaula
18225 Simi Valley
18226 San Francisco
18227 San Francisco
18228 Kingsville
18229 Chicago
18230 Pismo Beach
18231 Pismo Beach
18232 Lodi
18233 Anchorage
18234 Capitola
18235 Fountain Hills
18236 Grant Park
18237 Spirit Lake
18238 Eagle River
18239 Eagle River
18240 Ybor
Name: City, dtype: object
# confirm type
type(ufo['City'])
type(ufo.City)
Jupyter Output:
pandas.core.series.Series
Comment sélectionner une colonne qui contient des espaces ?
- Il n’est pas possible d’utiliser la méthode 2
ufo.category_name - Il faut utiliser la méthode 1
ufo['category name']
ufo['Colors Reported']
Jupyter Output:
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
5 NaN
6 NaN
7 NaN
8 NaN
9 NaN
10 NaN
11 NaN
12 RED
13 NaN
14 NaN
15 NaN
16 NaN
17 NaN
18 NaN
19 RED
20 NaN
21 NaN
22 NaN
23 NaN
24 NaN
25 NaN
26 NaN
27 NaN
28 NaN
29 NaN
...
18211 NaN
18212 NaN
18213 GREEN
18214 NaN
18215 NaN
18216 ORANGE
18217 NaN
18218 NaN
18219 NaN
18220 BLUE
18221 NaN
18222 NaN
18223 NaN
18224 NaN
18225 NaN
18226 NaN
18227 NaN
18228 NaN
18229 NaN
18230 NaN
18231 NaN
18232 NaN
18233 RED
18234 NaN
18235 NaN
18236 NaN
18237 NaN
18238 NaN
18239 RED
18240 NaN
Name: Colors Reported, dtype: object
Comment créer une nouvelle série Pandas dans un dataframe ?
# example of concatenating strings
'ab' + 'cd'
# created a new column called "Location" with a concatenation of "City" and "State"
ufo['Location'] = ufo.City + ', ' + ufo.State
ufo.head()
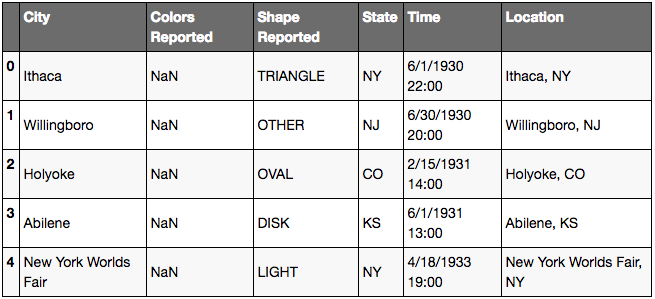
Parenthèses Pandas
Commandes Pandas finissant par des parenthèses
import pandas as pd
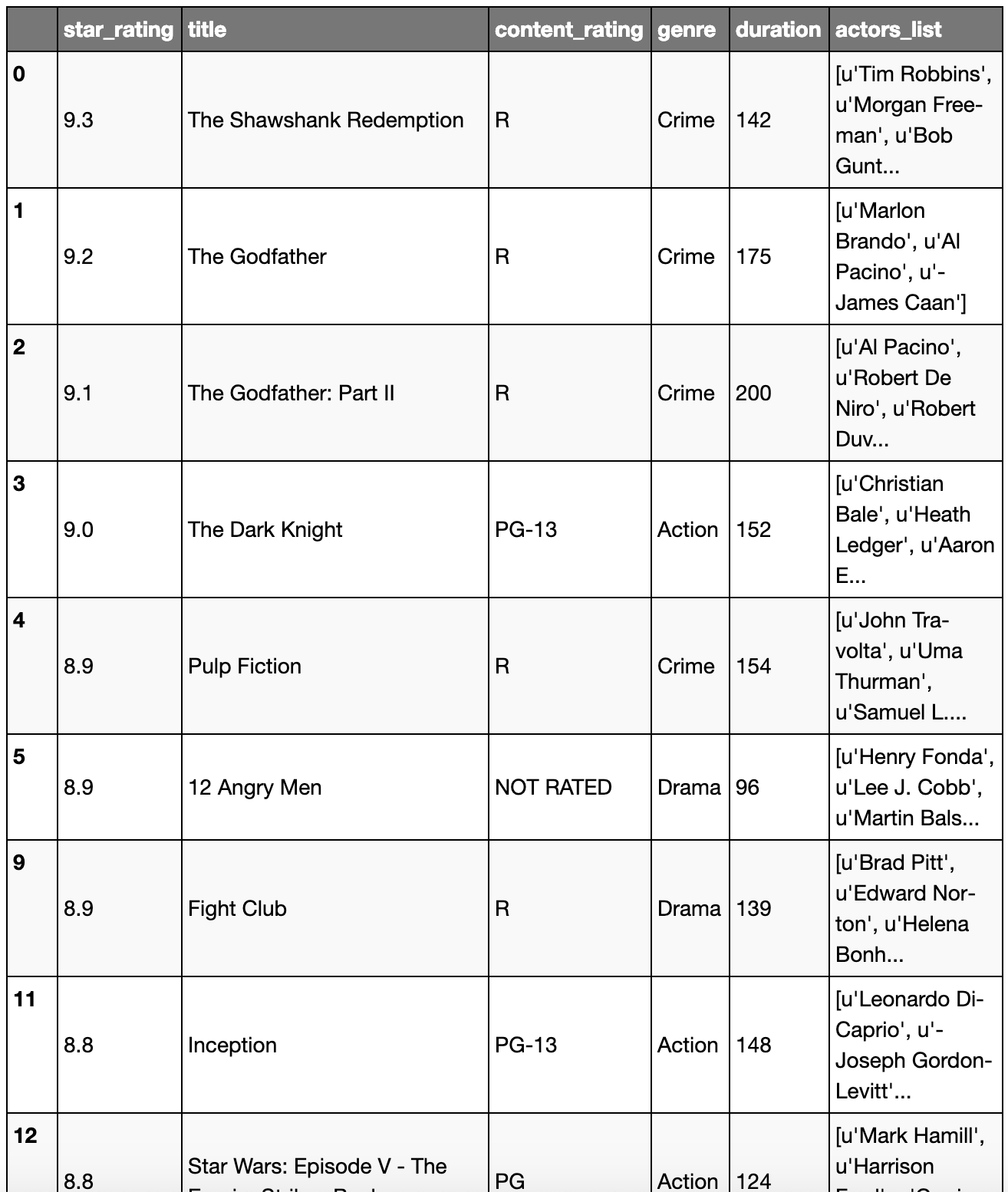
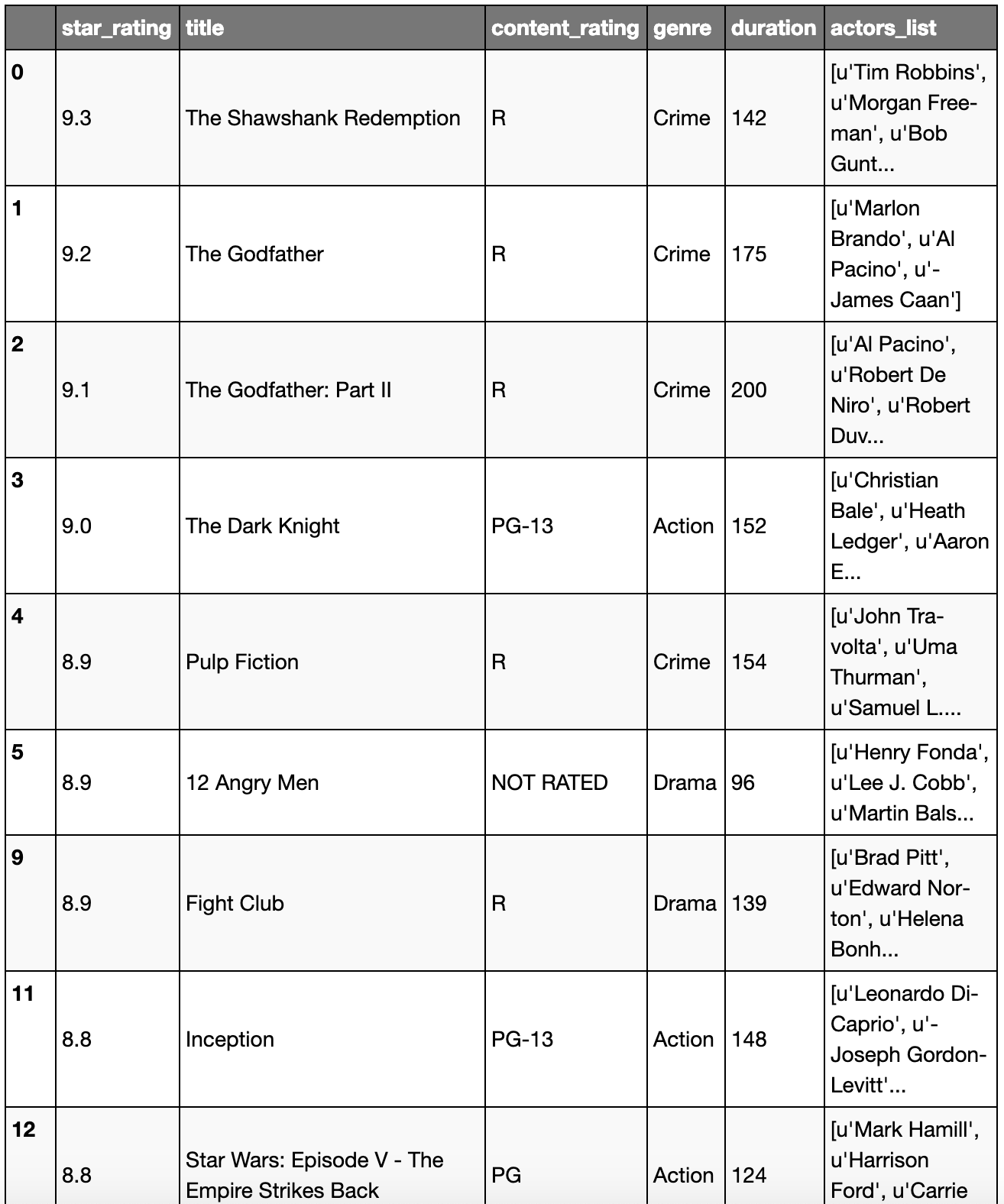
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/imdb_1000.csv'
movies = pd.read_csv(url)
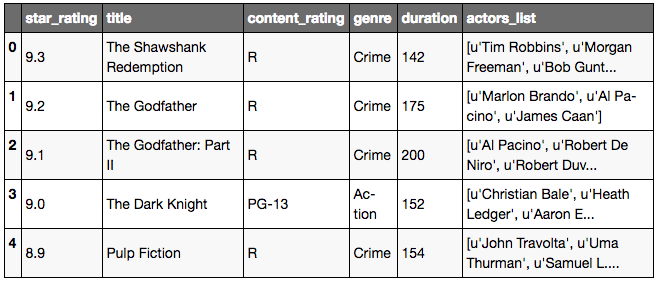
# Looking at the first 5 rows of the DataFrame
movies.head()
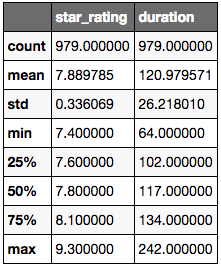
# This will show descriptive statistics of numeric columns
movies.describe()
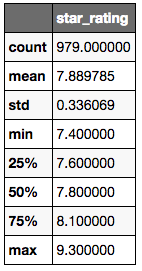
movies.describe(include=['float64'])
# Finding out dimensionality of DataFrame
movies.shape
Jupyter Output:
(979, 6)
# Finding out data types of each columns
movies.dtypes
Jupyter Output:
star_rating float64
title object
content_rating object
genre object
duration int64
actors_list object
dtype: object
type(movies)
Jupyter Output:
pandas.core.frame.DataFrame
Les dataframes ont certains attributs et méthodes
-
Méthodes: avec parenthèses
-
Orientées action:
movies.head()movies.describe()
-
Les parenthèses autorisent les arguments optionnels
movies.describe(include='object')
-
-
Attributs: sans parenthèse
- Orientés description:
movie.shape-movie.dtypes
- Orientés description:
Renommer des colonnes
import pandas as pd
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/ufo.csv'
ufo = pd.read_csv(url)
ufo.head()
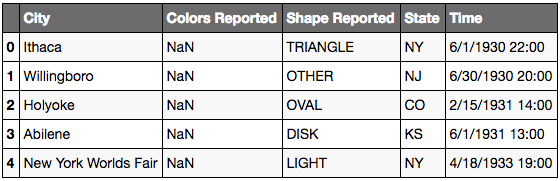
# To check out only the columns
# It will output a list of columns
ufo.columns
Jupyter Output:
Index(['City', 'Colors Reported', 'Shape Reported', 'State', 'Time'], dtype='object')
Méthode 1: Renommer une seule colonne:
# inplace=True to affect DataFrame
ufo.rename(columns = {'Colors Reported': 'Colors_Reported', 'Shape Reported': 'Shape_Reported'}, inplace=True)
ufo.columns
Jupyter Output:
Index(['City', 'Colors_Reported', 'Shape_Reported', 'State', 'Time'], dtype='object')
Méthode 2: renommer plusieurs colonnes:
ufo_cols = ['city', 'colors reported', 'shape reported', 'state', 'time']
ufo.columns = ufo_cols
ufo.head()
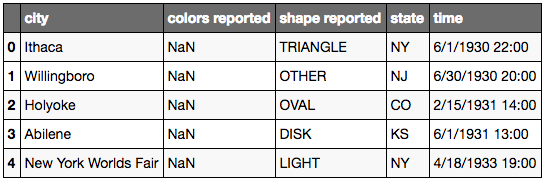
Méthode 3: Changer les colonnes pendant la lecture:
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/ufo.csv'
ufo = pd.read_csv(url, names=ufo_cols, header=0)
ufo.head()
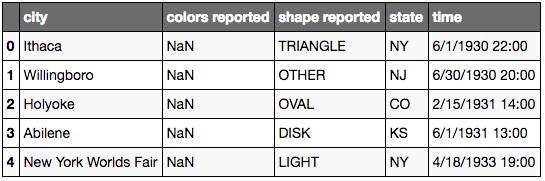
Méthode 4: replacer les espaces avec des underscores pour toutes les colonnes:
ufo.columns = ufo.columns.str.replace(' ', '_')
ufo.head()
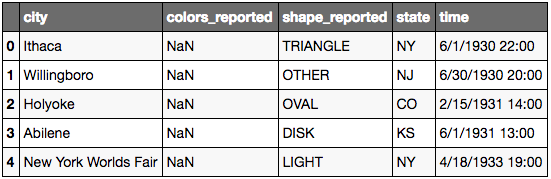
Effacer une colonne
import pandas as pd
# Creating pandas DataFrame
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/ufo.csv'
ufo = pd.read_csv(url)
ufo.head()
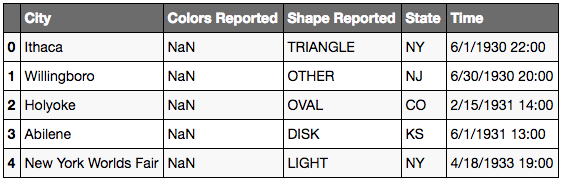
ufo.shape
Jupyter Output:
(18241, 5)
# Removing column
# axis=0 row axis
# axis=1 column axis
# inplace=True to effect change
ufo.drop('Colors Reported', axis=1, inplace=True)
ufo.head()
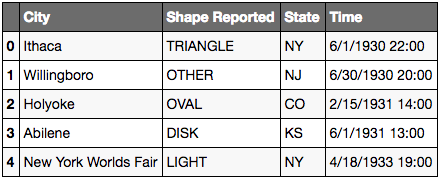
# Removing column
list_drop = ['City', 'State']
ufo.drop(list_drop, axis=1, inplace=True)
ufo.head()
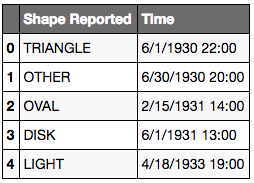
# Removing rows 0 and 1
# axis=0 is the default, so technically, you can leave this out
rows = [0, 1]
ufo.drop(rows, axis=0, inplace=True)
ufo.head()
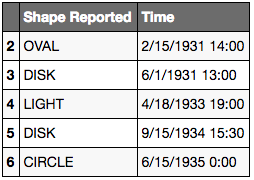
Effacer toutes les colonnes sauf certaine
# df d'origine
a b c d e f g
1 2 3 4 5 6 7
4 3 7 1 6 9 4
8 9 0 2 4 2 1
# df attendu
a b
1 2
4 3
8 9
df = df[['a','b']]
Trier
import pandas as pd
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/imdb_1000.csv'
movies = pd.read_csv(url)
movies.head()
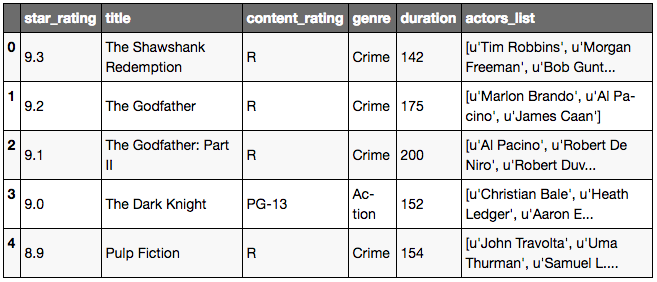
# sort using sort_values
# sort with numbers first then alphabetical order
movies.title.sort_values()
# alternative sorting
movies['title'].sort_values()
Jupyter Output:
542 (500) Days of Summer
5 12 Angry Men
201 12 Years a Slave
698 127 Hours
110 2001: A Space Odyssey
910 2046
596 21 Grams
624 25th Hour
708 28 Days Later...
60 3 Idiots
225 3-Iron
570 300
555 3:10 to Yuma
427 4 Months, 3 Weeks and 2 Days
824 42
597 50/50
203 8 1/2
170 A Beautiful Mind
941 A Bridge Too Far
571 A Bronx Tale
266 A Christmas Story
86 A Clockwork Orange
716 A Few Good Men
750 A Fish Called Wanda
276 A Fistful of Dollars
612 A Hard Day's Night
883 A History of Violence
869 A Nightmare on Elm Street
865 A Perfect World
426 A Prophet
...
207 What Ever Happened to Baby Jane?
562 What's Eating Gilbert Grape
719 When Harry Met Sally...
649 Where Eagles Dare
33 Whiplash
669 Who Framed Roger Rabbit
219 Who's Afraid of Virginia Woolf?
127 Wild Strawberries
497 Willy Wonka & the Chocolate Factory
270 Wings of Desire
483 Withnail & I
920 Witness
65 Witness for the Prosecution
970 Wonder Boys
518 Wreck-It Ralph
954 X-Men
248 X-Men: Days of Future Past
532 X-Men: First Class
871 X2
695 Y Tu Mama Tambien
403 Ying xiong
235 Yip Man
96 Yojimbo
280 Young Frankenstein
535 Zelig
955 Zero Dark Thirty
677 Zodiac
615 Zombieland
526 Zulu
864 [Rec]
Name: title, dtype: object
# returns a series
type(movies['title'].sort_values())
Jupyter Output:
pandas.core.series.Series
Tirer une colonne:
# sort in ascending=False
# this does not affect the underlying data
movies.title.sort_values(ascending=False)
Jupyter Output:
864 [Rec]
526 Zulu
615 Zombieland
677 Zodiac
955 Zero Dark Thirty
535 Zelig
280 Young Frankenstein
96 Yojimbo
235 Yip Man
403 Ying xiong
695 Y Tu Mama Tambien
871 X2
532 X-Men: First Class
248 X-Men: Days of Future Past
954 X-Men
518 Wreck-It Ralph
970 Wonder Boys
65 Witness for the Prosecution
920 Witness
483 Withnail & I
270 Wings of Desire
497 Willy Wonka & the Chocolate Factory
127 Wild Strawberries
219 Who's Afraid of Virginia Woolf?
669 Who Framed Roger Rabbit
33 Whiplash
649 Where Eagles Dare
719 When Harry Met Sally...
562 What's Eating Gilbert Grape
207 What Ever Happened to Baby Jane?
...
426 A Prophet
865 A Perfect World
869 A Nightmare on Elm Street
883 A History of Violence
612 A Hard Day's Night
276 A Fistful of Dollars
750 A Fish Called Wanda
716 A Few Good Men
86 A Clockwork Orange
266 A Christmas Story
571 A Bronx Tale
941 A Bridge Too Far
170 A Beautiful Mind
203 8 1/2
597 50/50
824 42
427 4 Months, 3 Weeks and 2 Days
555 3:10 to Yuma
570 300
225 3-Iron
60 3 Idiots
708 28 Days Later...
624 25th Hour
596 21 Grams
910 2046
110 2001: A Space Odyssey
698 127 Hours
201 12 Years a Slave
5 12 Angry Men
542 (500) Days of Summer
Name: title, dtype: object
Trieer un DataFrame en utilisant une colonne particulière:
movies.sort_values('title')
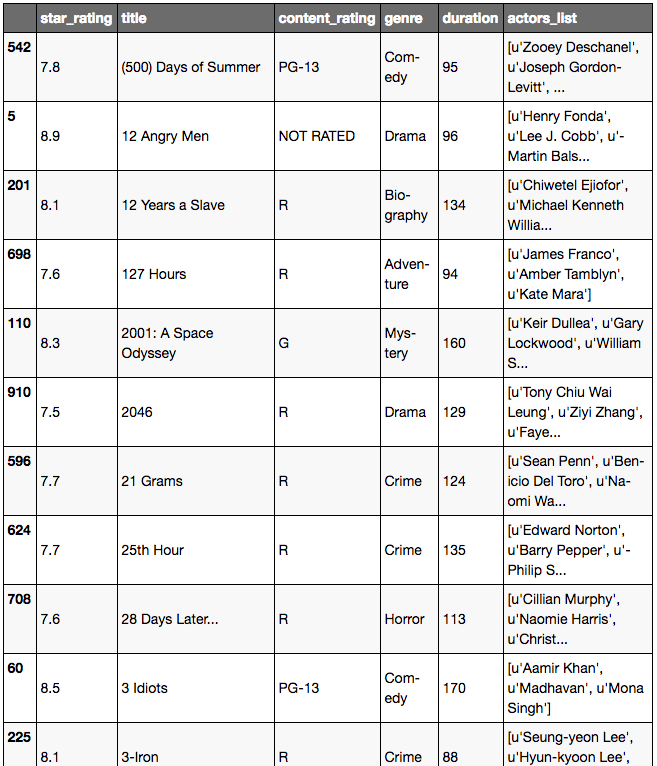
movies.sort_values('duration', ascending=False)
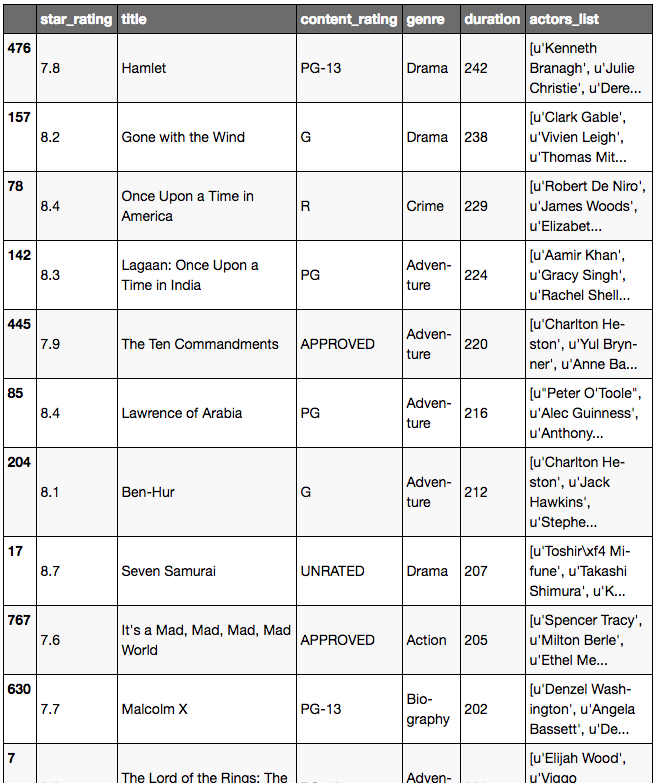
Trier un DataFrame en utilisant plusieurs colonnes:
# create list of columns
# sort using content_rating
# then within content_rating, sort by duration
columns = ['content_rating', 'duration']
# sort column
movies.sort_values(columns)
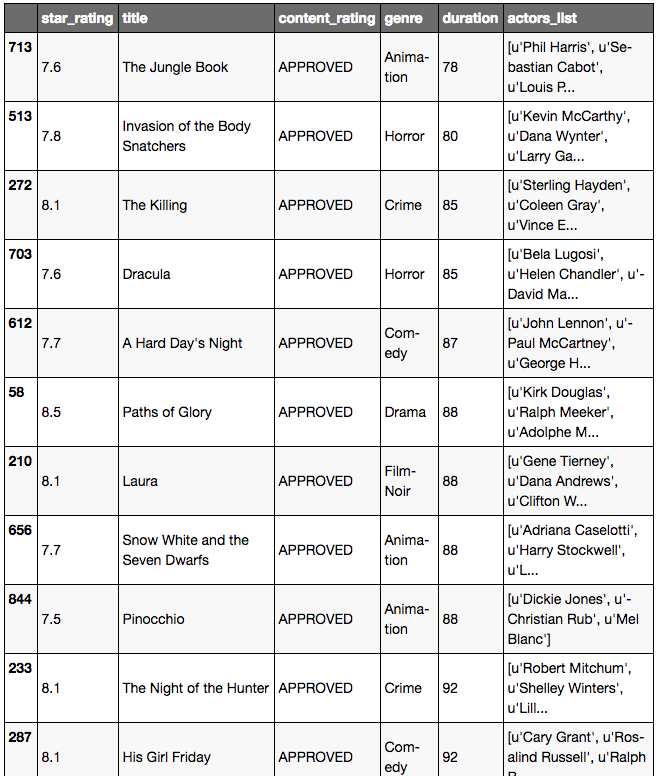
Filtrer
Filtrer les lignes d’un dataframe Pandas par rapport aux valeurs d’une colonne
import pandas as pd
# url
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/imdb_1000.csv'
# create DataFrame called movies
movies = pd.read_csv(url)
movies.head()
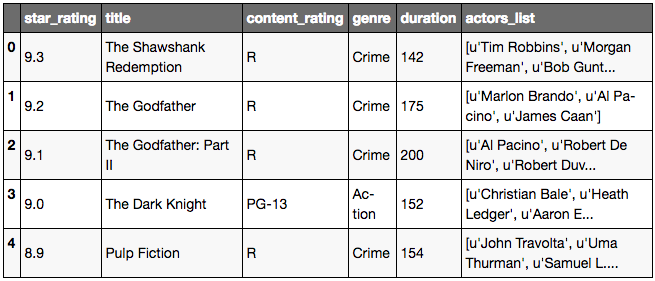
movies.shape
Jupyter Output:
(979, 6)
# booleans
type(True)
type(False)
Jupyter Output:
bool
On veut créer une liste de boolean avec le même nombre de lignes que le dataframe movies
- Le boolean vaudra true si la duration > 200
- false dans le cas contraire
# create list
booleans = []
# loop
for length in movies.duration:
if length >= 200:
booleans.append(True)
else:
booleans.append(False)
booleans[0:5]
Jupyter Output:
[False, False, True, False, False]
# len(booleans) is the same as the number of rows in movies' DataFrame
len(booleans)
Jupyter Output:
979
# convert booleans into a Pandas series
is_long = pd.Series(booleans)
is_long.head()
Jupyter Output:
0 False
1 False
2 True
3 False
4 False
dtype: bool
# pulls out genre
movies['genre']
Jupyter Output:
0 Crime
1 Crime
2 Crime
3 Action
4 Crime
5 Drama
6 Western
7 Adventure
8 Biography
9 Drama
10 Adventure
11 Action
12 Action
13 Drama
14 Adventure
15 Adventure
16 Drama
17 Drama
18 Biography
19 Action
20 Action
21 Crime
22 Drama
23 Crime
24 Drama
25 Comedy
26 Western
27 Drama
28 Crime
29 Comedy
...
949 Comedy
950 Crime
951 Drama
952 Comedy
953 Adventure
954 Action
955 Drama
956 Comedy
957 Comedy
958 Drama
959 Comedy
960 Comedy
961 Biography
962 Comedy
963 Action
964 Biography
965 Mystery
966 Animation
967 Action
968 Drama
969 Crime
970 Drama
971 Comedy
972 Drama
973 Drama
974 Comedy
975 Adventure
976 Action
977 Horror
978 Crime
Name: genre, dtype: object
# this pulls out duration >= 200mins
movies[is_long]
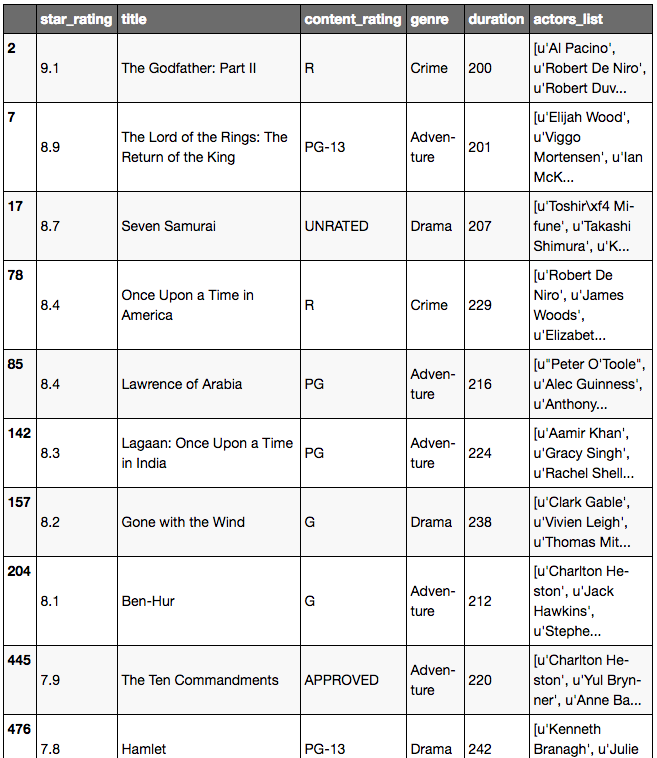
Méthode plus rapide sans for loop:
# this line of code replaces the for loop
# when you use a series name using pandas and use a comparison operator, it will loop through each row
is_long = movies.duration >= 200
is_long.head()
Jupyter Output:
0 False
1 False
2 True
3 False
4 False
Name: duration, dtype: bool
movies[is_long]
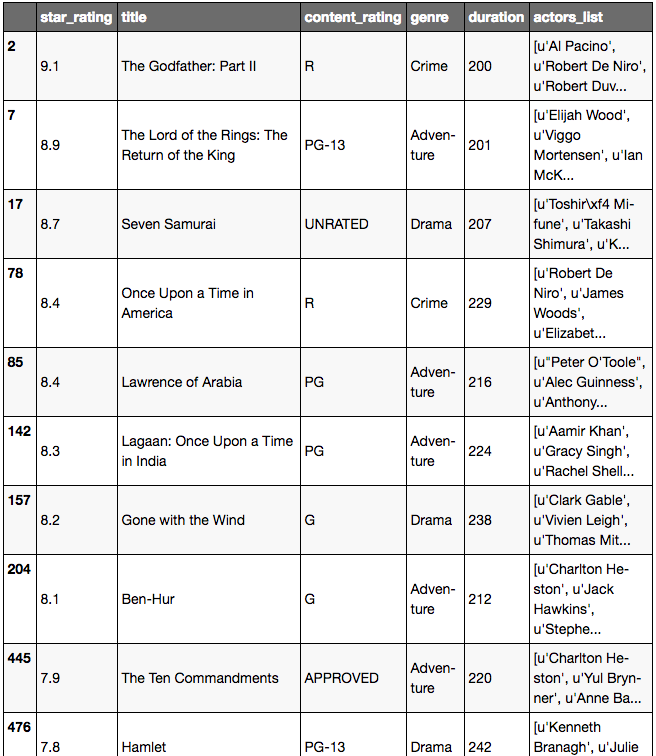
Méthode encore meilleure pour simplifier movies[is_long]:
movies[movies.duration >= 200]
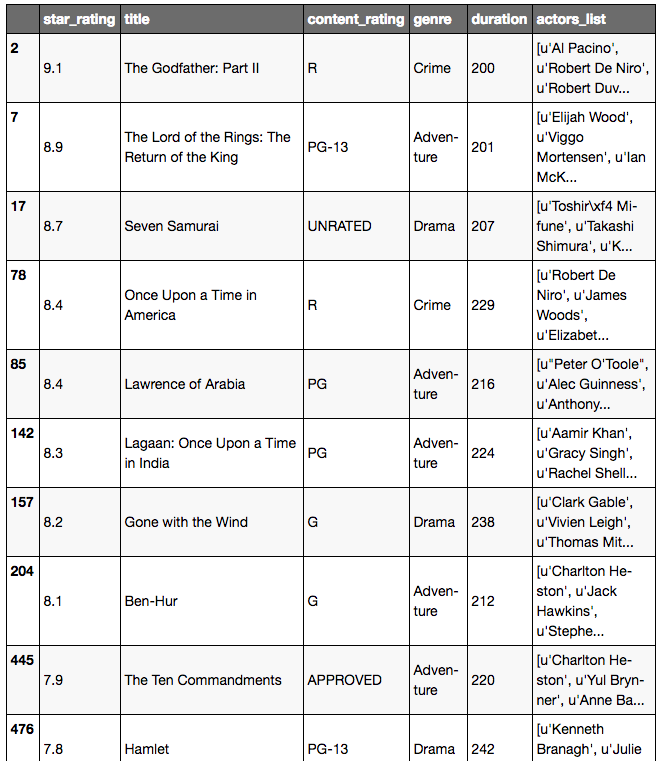
Conseil additionnel: on veut étudier la duration et seulement le genre au lieu de toutes les colonnes
# this is a DataFrame, we use dot or bracket notation to get what we want
movies[movies.duration >= 200]['genre']
movies[movies.duration >= 200].genre
Jupyter Output:
2 Crime
7 Adventure
17 Drama
78 Crime
85 Adventure
142 Adventure
157 Drama
204 Adventure
445 Adventure
476 Drama
630 Biography
767 Action
Name: genre, dtype: object
# best practice is to use .loc instead of what we did above by selecting columns
movies.loc[movies.duration >= 200, 'genre']
Jupyter Output:
2 Crime
7 Adventure
17 Drama
78 Crime
85 Adventure
142 Adventure
157 Drama
204 Adventure
445 Adventure
476 Drama
630 Biography
767 Action
Name: genre, dtype: object
Filtres multi-critères
Appliquer des filtres multi-critères sur un dataframe Pandas
import pandas as pd
url = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/imdb_1000.csv'
# Create movies DataFrame
movies = pd.read_csv(url)
movies.head()
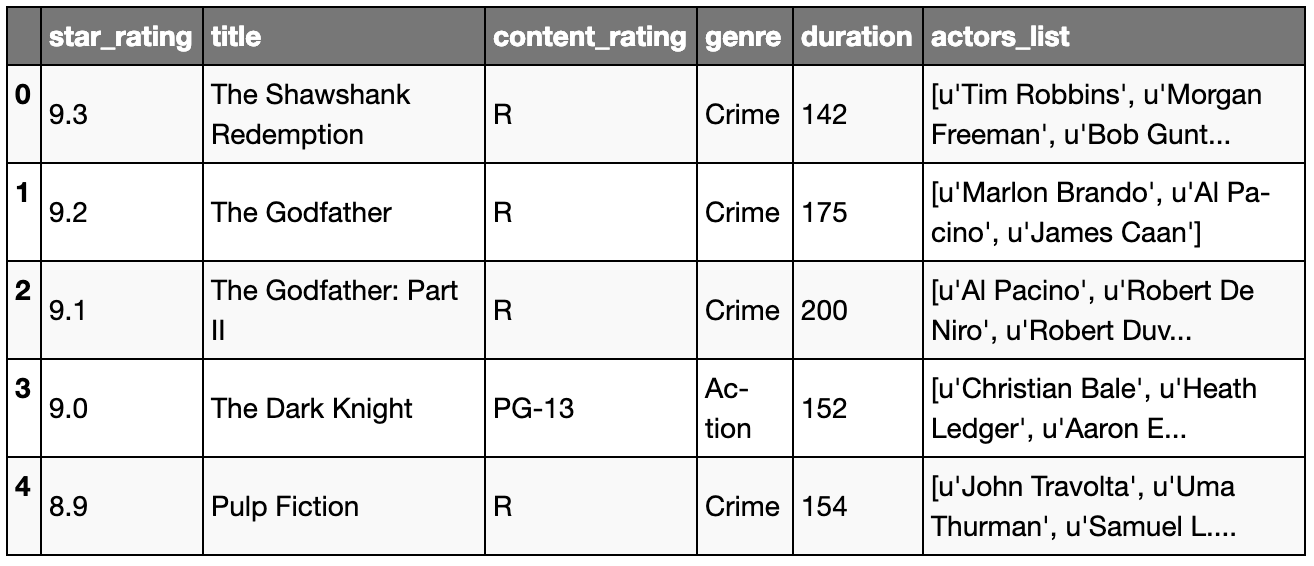
movies[movies.duration >= 200]
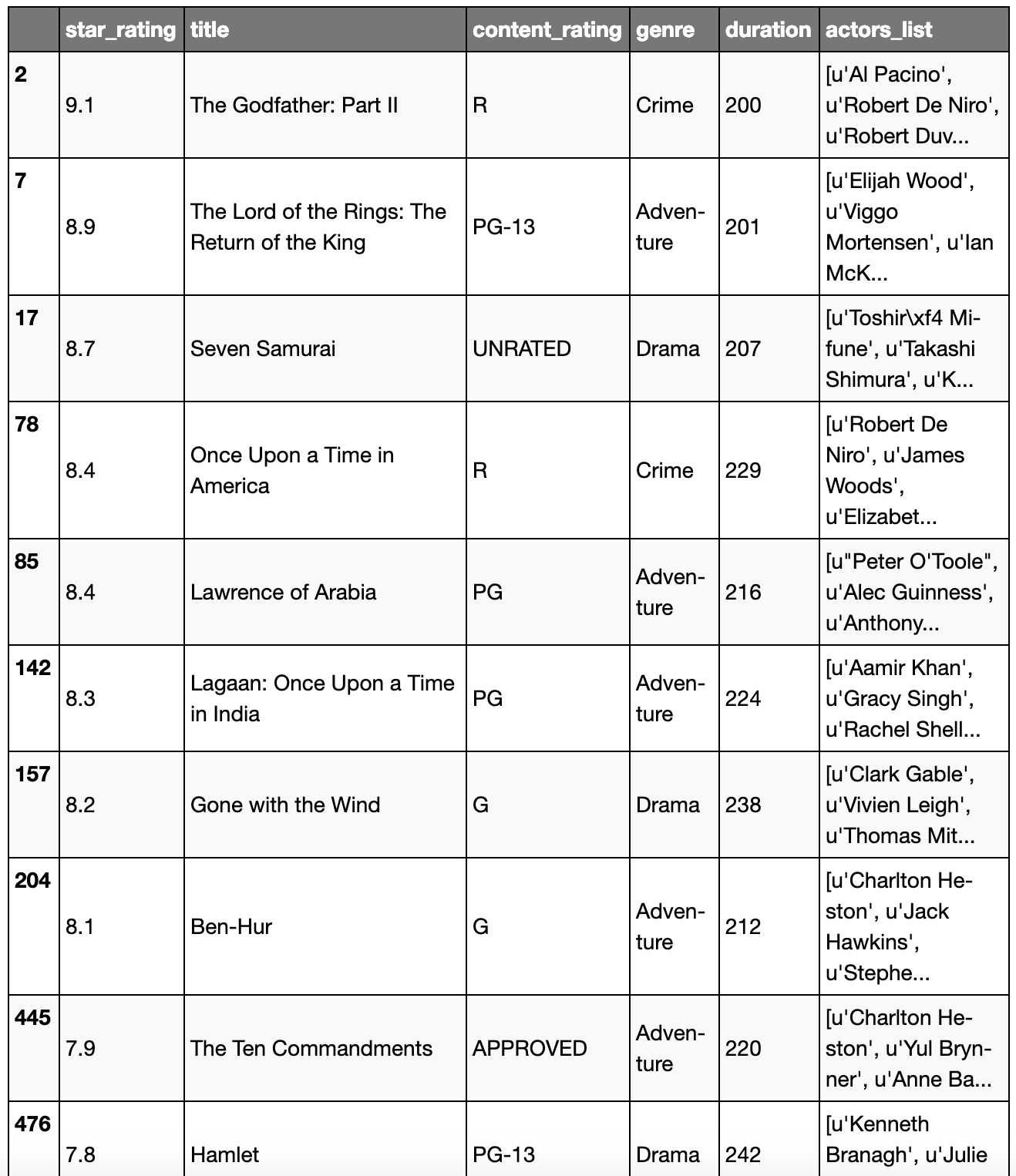
2 conditions
- duration > 200
- Seulement genre Drama
True or False
Output: True
True or True
Output: True
False or False
Output: False
True and True
Output: True
True and False
Output: False
# when you wrap conditions in parantheses, you give order
# you do those in brackets first before 'and'
# AND
movies[(movies.duration >= 200) & (movies.genre == 'Drama')]
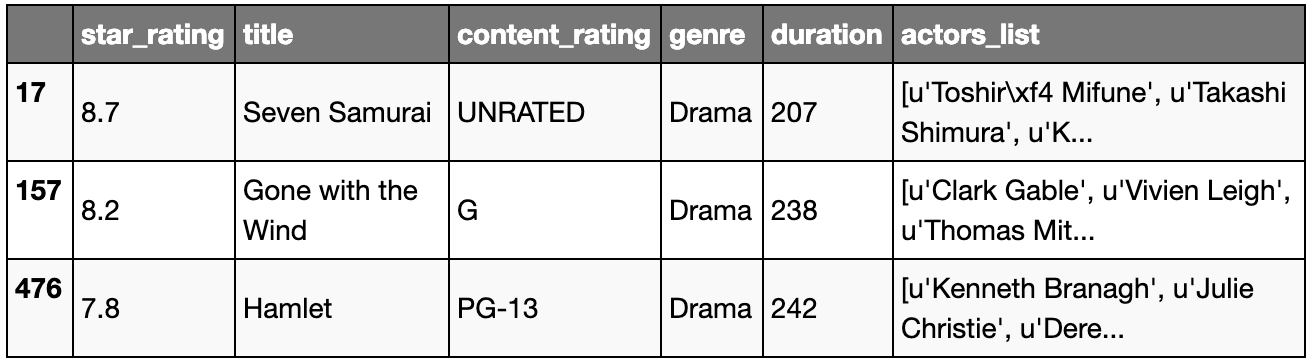
# OR
movies[(movies.duration >= 200) | (movies.genre == 'Drama')]
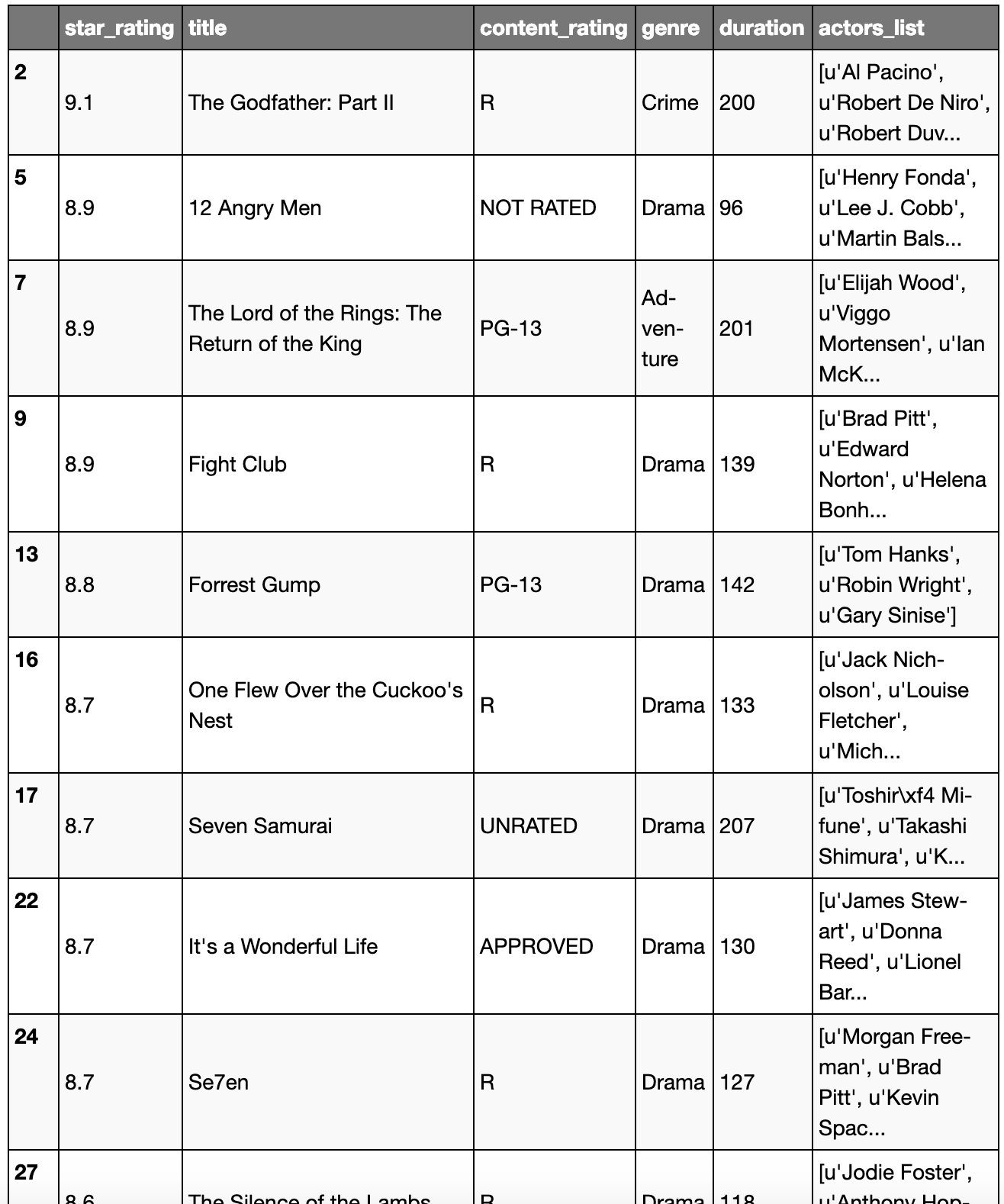
(movies.duration >= 200) | (movies.genre == 'Drama')
Jupyter Output:
0 False
1 False
2 True
3 False
4 False
5 True
6 False
7 True
8 False
9 True
10 False
11 False
12 False
13 True
14 False
15 False
16 True
17 True
18 False
19 False
20 False
21 False
22 True
23 False
24 True
25 False
26 False
27 True
28 False
29 False
...
949 False
950 False
951 True
952 False
953 False
954 False
955 True
956 False
957 False
958 True
959 False
960 False
961 False
962 False
963 False
964 False
965 False
966 False
967 False
968 True
969 False
970 True
971 False
972 True
973 True
974 False
975 False
976 False
977 False
978 False
dtype: bool
(movies.duration >= 200) & (movies.genre == 'Drama')
Jupyter Output:
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 False
10 False
11 False
12 False
13 False
14 False
15 False
16 False
17 True
18 False
19 False
20 False
21 False
22 False
23 False
24 False
25 False
26 False
27 False
28 False
29 False
...
949 False
950 False
951 False
952 False
953 False
954 False
955 False
956 False
957 False
958 False
959 False
960 False
961 False
962 False
963 False
964 False
965 False
966 False
967 False
968 False
969 False
970 False
971 False
972 False
973 False
974 False
975 False
976 False
977 False
978 False
dtype: bool
Et si on veut les genres crime, drama, et action?
# slow method
movies[(movies.genre == 'Crime') | (movies.genre == 'Drama') | (movies.genre == 'Action')]
# fast method
filter_list = ['Crime', 'Drama', 'Action']
movies[movies.genre.isin(filter_list)]
Examiner un dataset
Lire un sous-ensemble de colonnes ou lignes
import pandas as pd
link = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/ufo.csv'
ufo = pd.read_csv(link)
ufo.columns
Jupyter Output:
Index(['City', 'Colors Reported', 'Shape Reported', 'State', 'Time'], dtype='object')
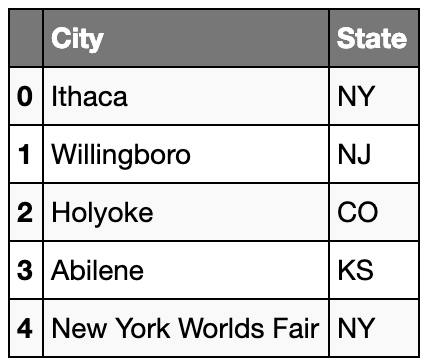
# reference using String
cols = ['City', 'State']
ufo = pd.read_csv(link, usecols=cols)
ufo.head()
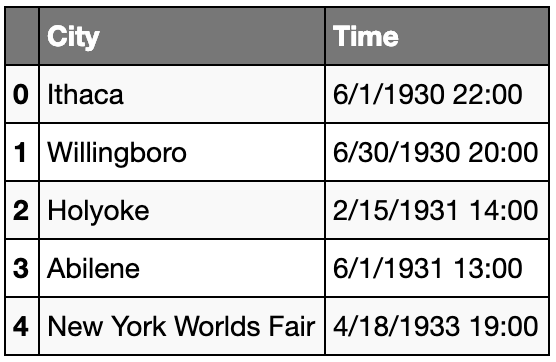
# reference using position (Integer)
cols2 = [0, 4]
ufo = pd.read_csv(link, usecols=cols2)
ufo.head()
# if you only want certain number of rows
ufo = pd.read_csv(link, nrows=3)
ufo
Itérer dans une série et un dataframe
# intuitive method
for c in ufo.City:
print(c)
Jupyter Output:
Ithaca
Willingboro
Holyoke
# pandas method
# you can grab index and row
for index, row in ufo.iterrows():
print(index, row.City, row.State)
Jupyter Output:
0 Ithaca NY
1 Willingboro NJ
2 Holyoke CO
Retirer les colonnes non-numeriques d’un DataFrame
link = 'https://raw.githubusercontent.com/justmarkham/pandas-videos/master/data/drinks.csv'
drinks = pd.read_csv(link)
# you have 2 non-numeric columns
drinks.dtypes
Jupyter Output:
country object
beer_servings int64
spirit_servings int64
wine_servings int64
total_litres_of_pure_alcohol float64
continent object
dtype: object
import numpy as np
drinks.select_dtypes(include=[np.number]).dtypes
Jupyter Output:
beer_servings int64
spirit_servings int64
wine_servings int64
total_litres_of_pure_alcohol float64
dtype: object
Numéro, index et contenu de la ligne lors d’une itération
Pour obtenir le numéro, l’index et le contenu de la ligne lors d’une itération on peut utiliser le code suivant:
for line_number, (idx, row) in enumerate(df.iterrows()):
...