4 minutes
Diviser par 5 la durée d’apprentissage de son réseau de neurones profonds
Avec l’engouement des Chatbots et l’émergence de nouveaux services SAAS, je me suis dit qu’il fallait que je regarde de plus près comment cela fonctionne…
J’ai d’abord testé des solutions Cloud et notamment le nouveau service d’AWS Amazon Lex et il faut avouer que la mise en place est vraiment simple. Ils proposent une intégration sur mobile natif via un SDK et une intégration sur Web avec un simple script JS. En 1 heure vous pouvez avoir à disposition un Chatbot et exécuter des actions en fonction des intents que vous avez configuré. Le Chatbot peut communiquer avec AWS Lambda.
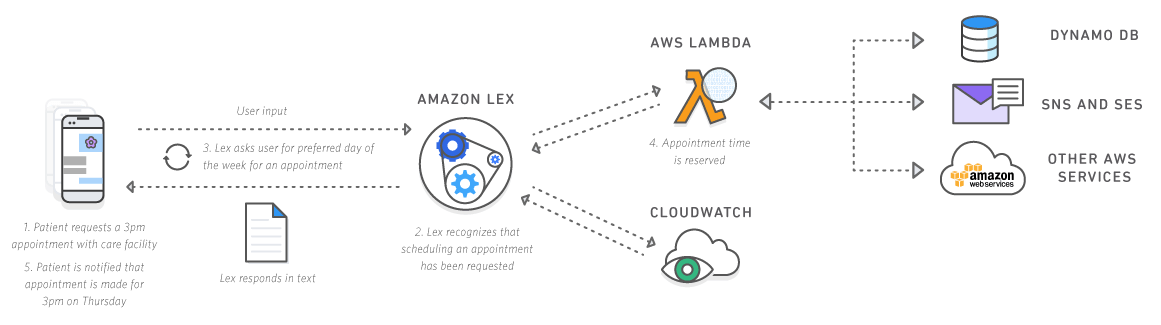
Source: Amazon
J’ai également testé le service conversation de Watson et idem la mise en place est aisée. Il y a projet boilerplate en NodeJS sur Github: https://github.com/watson-developer-cloud/conversation-simple; ainsi qu’un Chatbot de démo plutôt bien fait: https://conversation-demo.mybluemix.net/
(On m’a aussi parlé des services Wit.ai et API.ai . Je n’ai pas encore testé)
Dans un but pédagogique, j’ai voulu implémenter un Chatbot maison un mon propre réseau neuronal. Je me suis donc inspiré d’un papier écrit par un ingénieur chez Google et créé un modèle Seq2Seq avec un RNN (Recurrent Neural Network).
Dans cet article, je ne vais pas m’entendre sur le RNN ou le modèle Seq2Seq. (Cela pourrait faire l’objet d’un autre article…)
Ce dont je voulais parler dans cet article c’est comment j’ai divisé par 5 le temps d’apprentissage de mon Recurrent Neural Network !
C’est tout simplement grâce aux GPU ! Et dans mon cas précis grâce aux GPU d’Amazon Web Services.

Jusqu’à présent, lorsque je voulais entraîner mes réseaux de neurones profonds, j’utilisais le CPU de mon Mac Pro. Entraîner un réseau avec un corpus d’environ 220 000 conversations m’a pris environ 3600 minutes soit 2,5 jours. En utilisant le GPU d’une instance AWS, je suis passé à une demi journée et je pense cela peut encore être optimisé. En effet, je n’ai pas loué les machines avec les plus grosses cartes graphiques…
L’autre gros travail que j’ai fait est de complètement Dockeriser mon projet et faire en sorte que le container Docker puisse accéder au GPU du Host.
Pour ce faire, j’ai utilisé la technologie Compute Unified Device Architecture (CUDA) et un projet open source appelé nvidia-docker.

Voici un lien intéressants pour comprendre ce qu’est CUDA: https://fr.wikipedia.org/wiki/Compute_Unified_Device_Architecture
Le gros intérêt d’avoir Dockerisé mon projet est que je peux le faire tourner n’importe où. Bien sûr, si je veux bénéficier de performances optimales pour entraîner mon RNN, il me faut un bon GPU et un GPU de la marque Nvidia.
Voici la procédure à suivre pour faire tourner TensorFlow sur des GPUs sur AWS:
Commencez par démarrer une instance sur AWS. Avec les commandes que vous trouverez ci-dessous, je vous conseille de démarrer une Instance Ubuntu 16.04 LTS:

Choisissez ensuite une instance de type p2 ou g2:


Récupérez l’adresse IP publique de votre instance et connectez vous en SSH
ssh -i ~/.ssh/<votre-fichier-pem> ubuntu@<addresse-ip>
Installer le dernier Driver Nvidia
$ apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub
$ sh -c 'echo "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64 /" && /etc/apt/sources.list.d/cuda.list'
$ apt-get update
$ apt-get install -y --no-install-recommends cuda-drivers
Installer la dernière version de Docker (tutorial réalisé avec Docker 1.13)
$ apt-get update
$ curl -fsSL https://get.docker.com/ | sh
$ curl -fsSL https://get.docker.com/gpg | sudo apt-key add -
Installer Nvidia Docker
$ wget https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.0/nvidia-docker_1.0.0-1_amd64.deb
$ dpkg -i nvidia-docker_1.0.0-1_amd64.deb
$ rm nvidia-docker_1.0.0-1_amd64.deb
Téléchargez l’image Docker TensorFlow GPU
$ docker pull tensorflow/tensorflow:latest-gpu
Démarrez ensuite un container Docker depuis l’image téléchargée. Je vous conseille d’exposer les ports 6006 et 8888 pour tensorboard et Jupyter Notebook.
$ nvidia-docker run -itd --name=gpu-tensorflow -p 8888:8888 -p 6006:6006 tensorflow/tensorflow:latest-gpu
Vous pouvez à présent vous connecter en SSH dans le container Docker et utiliser TensorFlow. Python 3 devrait être installé.
$ sudo nvidia-docker exec -it gpu-tensorflow bash
La commande suivante vous permettra de vérifier qu’il y a bien une carte GPU accessible:
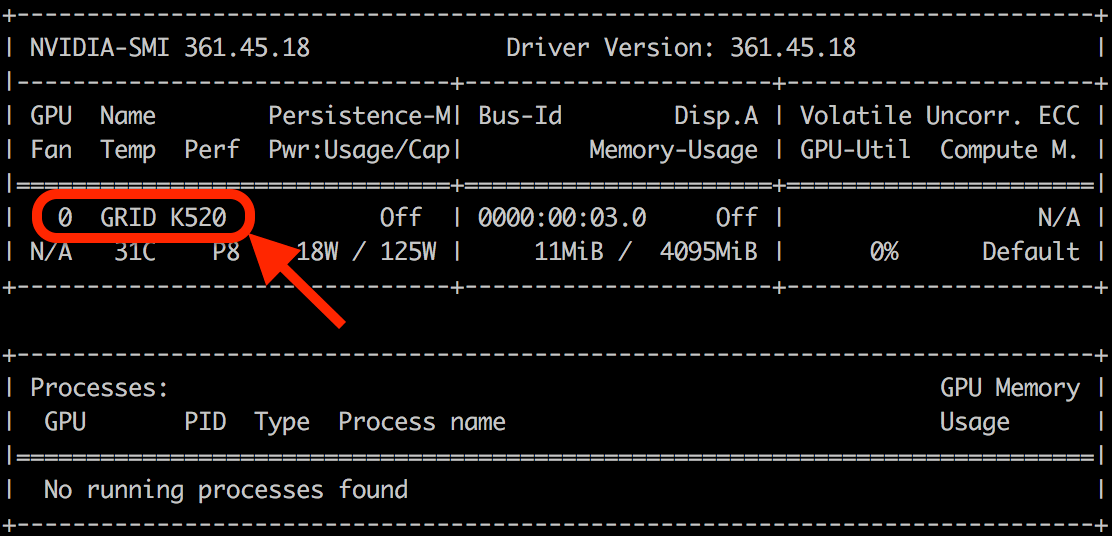
$ nvidia-smi
Par exemple avec une instance g2.2xlarge (1 Nvidia K520 GPU), vous devriez voir ceci:
Il ne vous reste plus qu’à cloner votre projet TensorFlow et à l’exécuter.
Si vous ne l’avez pas configuré autrement, vous devriez voir que TensorFlow utilise bien le GPU.

Lorsque vous avez terminé, n’oubliez pas d’éteindre votre instance AWS; surtout si vous choisissez une instance p2. Attention à la facture !
C’est d’ailleurs un point d’amélioration que j’aimerais apporter à ce projet. J’aimerais automatiser la création d’instance AWS via un bot ou un script, que TensorFlow entraîne automatiquement le modèle pendant plusieurs heures et que la VM soit automatiquement terminated lorsque l’apprentissage est achevé. J’aimerais évidemment que le modèle généré par TensorFlow soit sauvegardé dans un Bucket S3.
Pour info, voici les commandes à utiliser pour désinstaller complètement Docker sur Ubuntu. J’ai rencontré des difficultés avec des versions de Docker non compatibles avec nvidia-docker. Ces commandes pourraient aider:
$ apt-get purge docker-engine
$ apt-get autoremove --purge docker-engine
$ rm -rf /var/lib/docker