4 minutes
Commandes Python de base pour faire une régression en apprentissage supervisé avec scikit
Dans cet article nous allons travailler sur le dataset “Boston house prices” de scikit-learn et essayer de prédire le prix de l’immobilier. Nous allons prédire une le prix d’une maison; ce qui signifie prédire une valeur continue.
Le dataset ressemble à ceci:
from sklearn.datasets import load_boston
import pandas as pd
data = load_boston()
print(data.data.shape)
print(data.target.shape)
df_data = pd.DataFrame(data.data, columns=data.feature_names)
df_labels = pd.DataFrame(data.target, columns=['price in $1000\'s'])
df_total = pd.concat([df_data, df_labels], axis=1)
print(df_total.head(5))
Résultat:
(506, 13)
(506,)
CRIM ZN INDUS CHAS NOX RM AGE DIS RAD TAX \
0 0.00632 18.0 2.31 0.0 0.538 6.575 65.2 4.0900 1.0 296.0
1 0.02731 0.0 7.07 0.0 0.469 6.421 78.9 4.9671 2.0 242.0
2 0.02729 0.0 7.07 0.0 0.469 7.185 61.1 4.9671 2.0 242.0
3 0.03237 0.0 2.18 0.0 0.458 6.998 45.8 6.0622 3.0 222.0
4 0.06905 0.0 2.18 0.0 0.458 7.147 54.2 6.0622 3.0 222.0
PTRATIO B LSTAT price in $1000's
0 15.3 396.90 4.98 24.0
1 17.8 396.90 9.14 21.6
2 17.8 392.83 4.03 34.7
3 18.7 394.63 2.94 33.4
4 18.7 396.90 5.33 36.2
La librairie Pandas est une librairie parfaite pour manipuler les données. Nous avons déjà parlé de cette librairie dans l’article [article à indiquer].
Les features CRIM, ZN, INDUS, CHAS, NOX,… ne veulent rien dire comme cela. Il y a un descriptif dans l’objet data qui permet de mieux comprendre à quoi correspond ces abréviations.
print(data.DESCR)
Résultat:
Boston House Prices dataset
===========================
Notes
------
Data Set Characteristics:
:Number of Instances: 506
:Number of Attributes: 13 numeric/categorical predictive
:Median Value (attribute 14) is usually the target
:Attribute Information (in order):
- CRIM per capita crime rate by town
- ZN proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS proportion of non-retail business acres per town
- CHAS Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX nitric oxides concentration (parts per 10 million)
- RM average number of rooms per dwelling
- AGE proportion of owner-occupied units built prior to 1940
- DIS weighted distances to five Boston employment centres
- RAD index of accessibility to radial highways
- TAX full-value property-tax rate per $10,000
- PTRATIO pupil-teacher ratio by town
- B 1000(Bk - 0.63)^2 where Bk is the proportion of blacks by town
- LSTAT % lower status of the population
- MEDV Median value of owner-occupied homes in $1000's
:Missing Attribute Values: None
...
Visualisation des données et sélection des features
On va commencer par visualiser les données pour essayer de comprendre de à quoi ressemble le dataset. L’objectif n’est pas de tout visualiser et de tout comprendre tout de suite; l’objectif est plus d’avoir une première idée de ce à quoi ressemblent les données.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
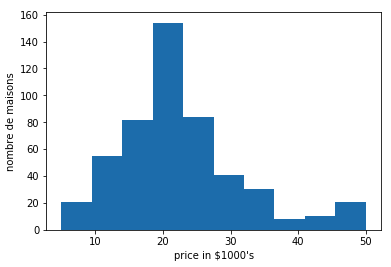
plt.hist(data.target)
plt.xlabel('price in $1000\'s')
plt.ylabel('nombre de maisons')
Résultat:
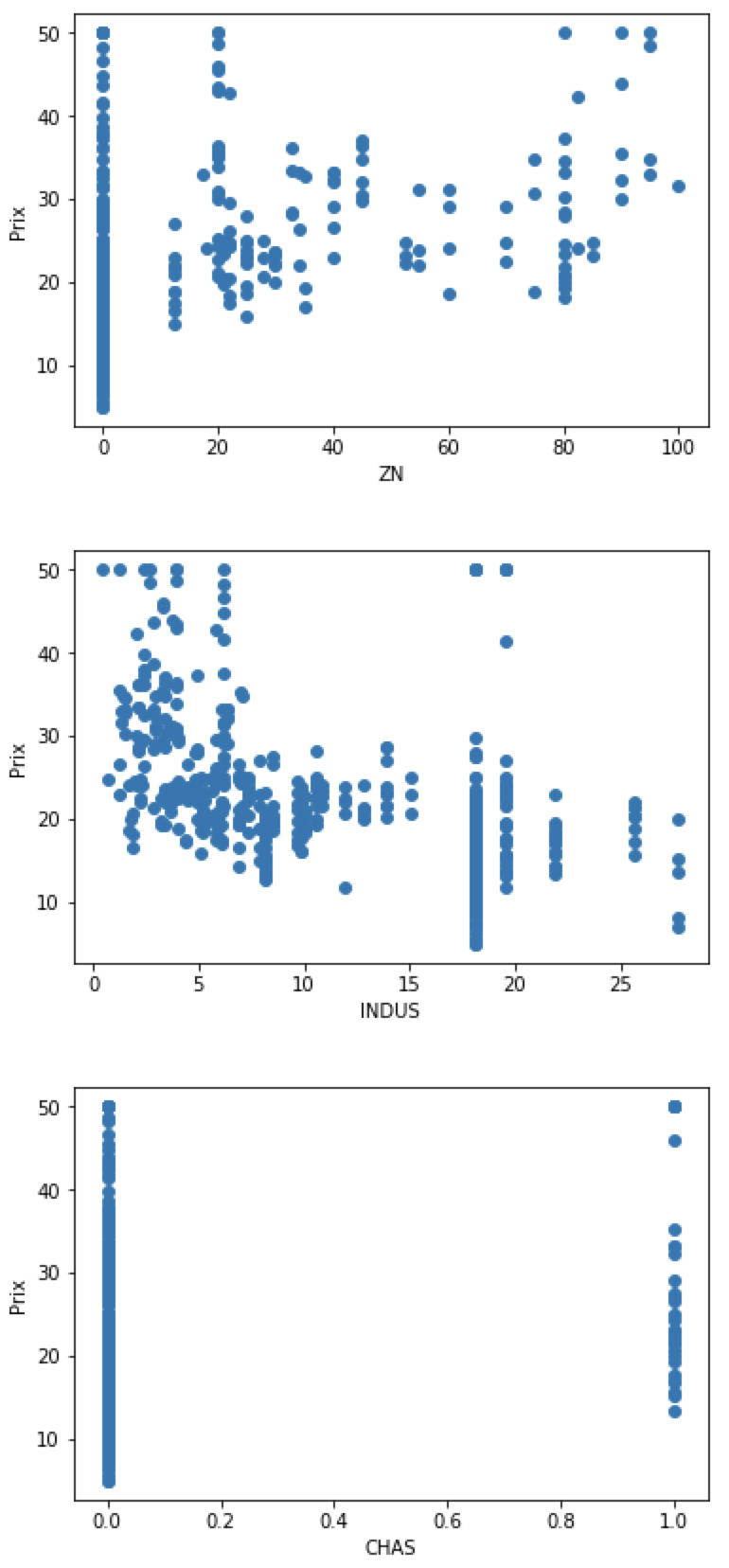
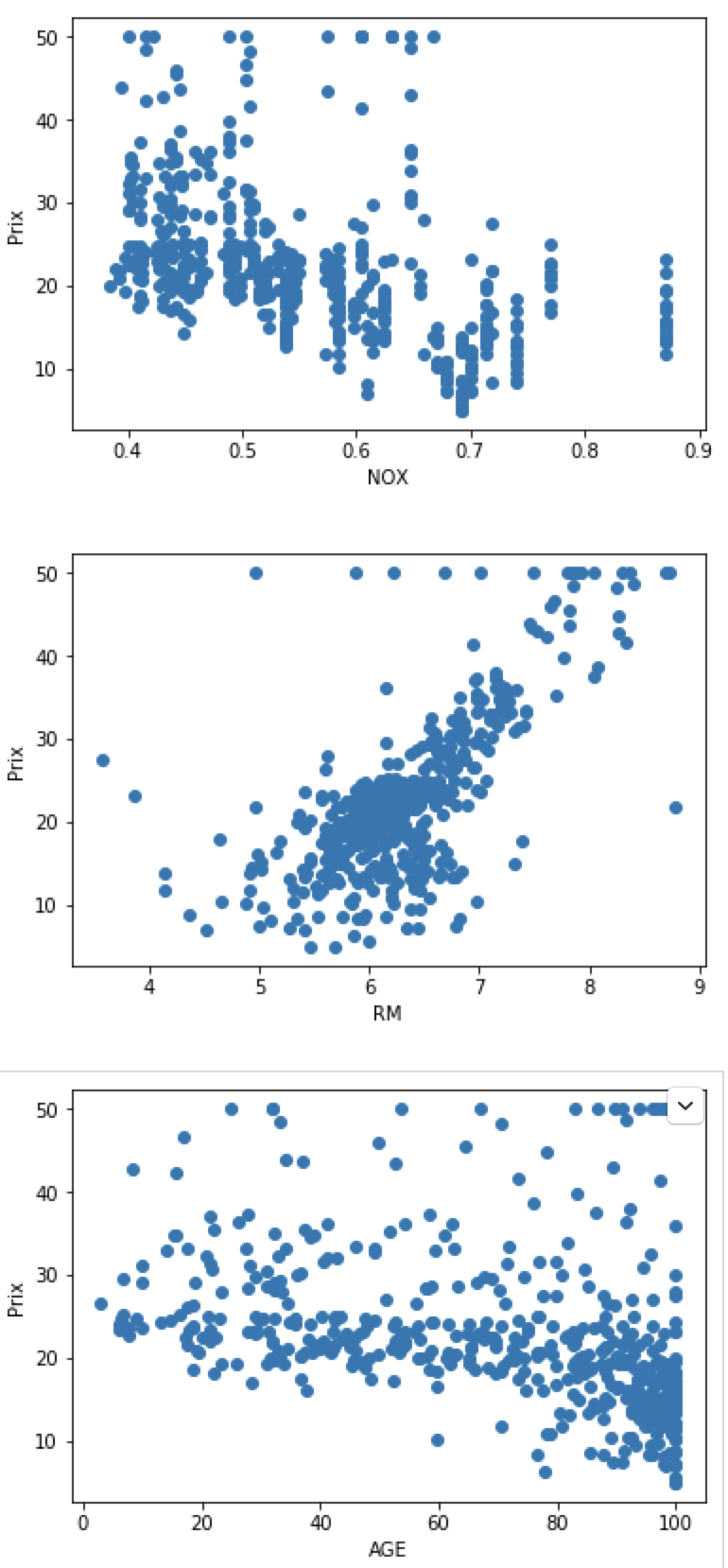
On va sélectionner les features qui influent le plus le prix des maisons. On va afficher sur un graphique chaque feature et retenir celles qui sont les plus corrélées avec notre cible. Cette étape est faite manuellement. Nous aurions pu le faire automatiquement. Nous verrons ces techniques dans un prochain article.
for index, feature_name in enumerate(data.feature_names):
plt.figure()
plt.scatter(data.data[:, index], data.target)
plt.ylabel('Prix')
plt.xlabel(feature_name)
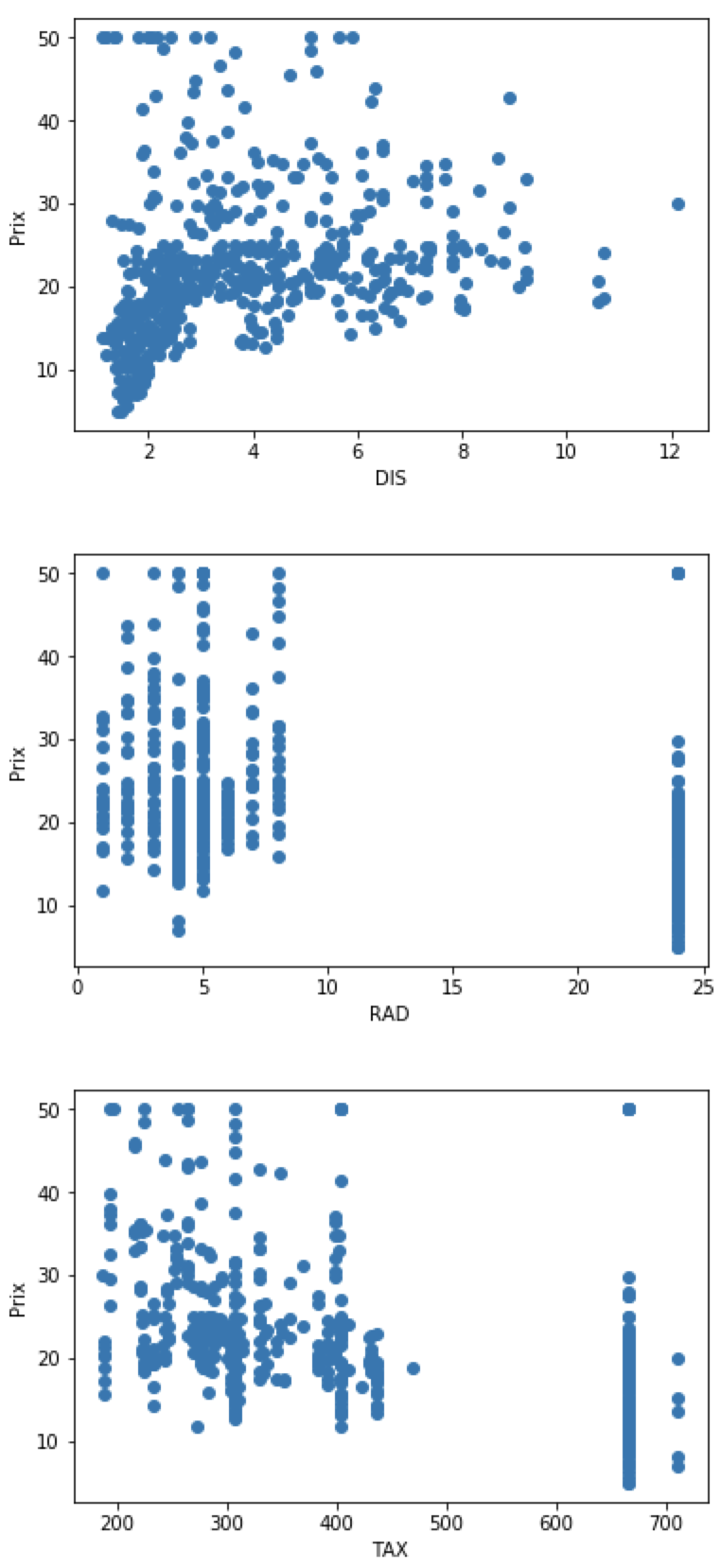
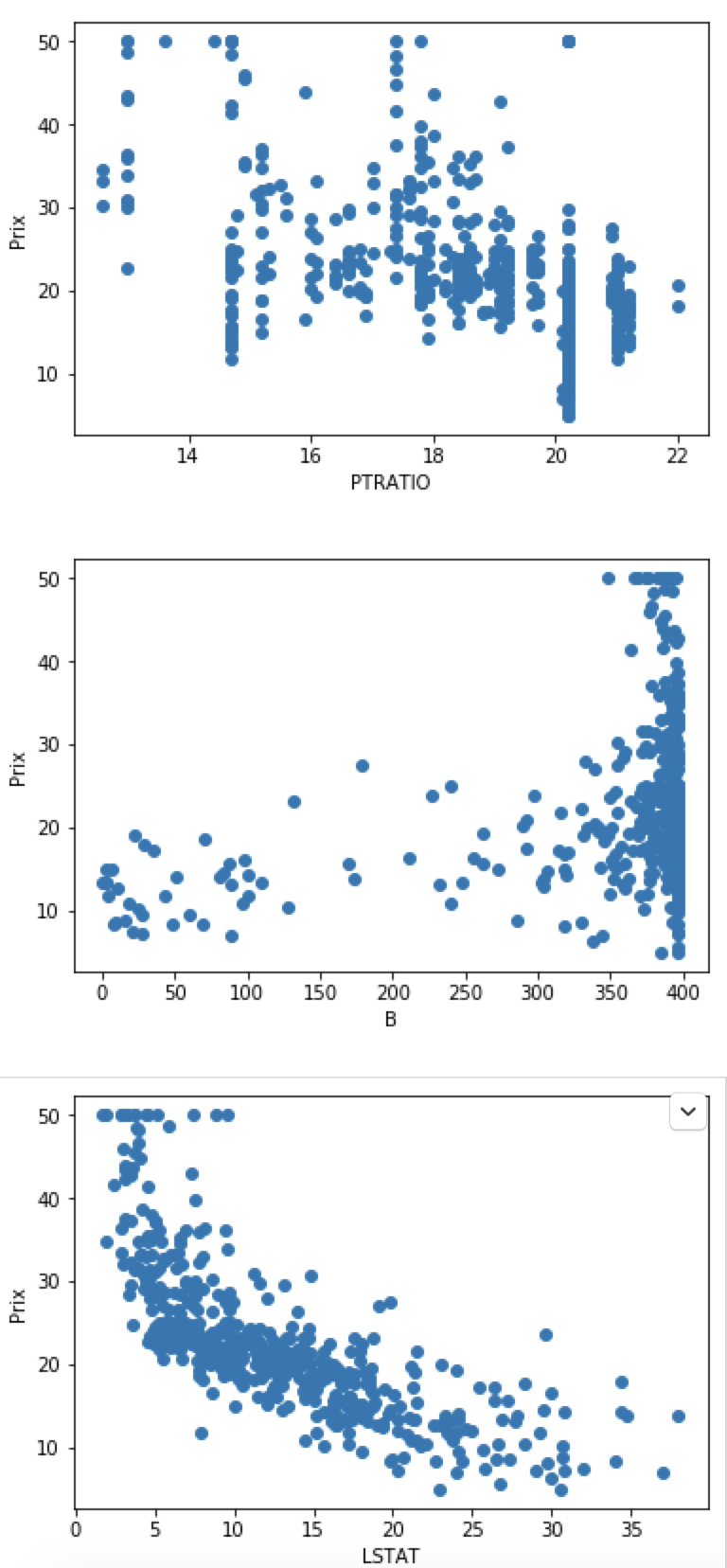
Prédire le prix de l’immobilier
Régression linéaire
A présent nous allons construire notre modèle de régression linéaire (calcul des moindres carrés) sur l’ensemble des données.
Cette méthode consiste à déterminer la droite théorique dont les coordonnées sont la moyenne arithmétique de toutes les données. Pour faire plus simple, c’est la droite qui passe au plus près de tous les points de données.
from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target)
from sklearn.linear_model import LinearRegression
estimator = LinearRegression()
estimator.fit(X_train, y_train)
predicted = estimator.predict(X_test)
expected = y_test
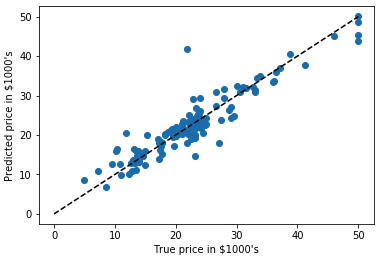
plt.scatter(expected, predicted)
plt.plot([0, 50], [0, 50], '--k')
plt.axis('tight')
plt.xlabel('True price in $1000\'s')
plt.ylabel('Predicted price in $1000\'s')
print("RMS:", np.sqrt(np.mean((predicted - expected) ** 2)))
Résultat:
RMS: 4.683413955906375
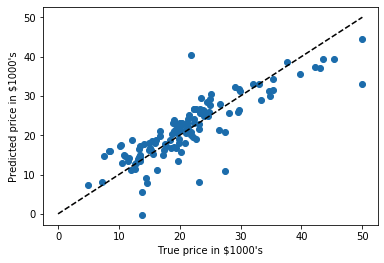
On voit qu’il y a une correlation entre le prix prédit et le vrai prix des maisons; même s’il y a quand même pas mal de biais.
Arbre de décision Gradient Boosting
On va utiliser un meilleur régresseur pour obtenir un meilleur résultat.
from sklearn.ensemble import GradientBoostingRegressor
clf = GradientBoostingRegressor()
clf.fit(X_train, y_train)
predicted = clf.predict(X_test)
expected = y_test
plt.scatter(expected, predicted)
plt.plot([0, 50], [0, 50], '--k')
plt.axis('tight')
plt.xlabel('True price in $1000\'s')
plt.ylabel('Predicted price in $1000\'s')
print("RMS:", np.sqrt(np.mean((predicted - expected) ** 2)))
Résultat:
RMS: 3.2226035734196445